Workflow¶
FeatureByte provides a comprehensive workflow from setting up a feature store to serving and managing features.
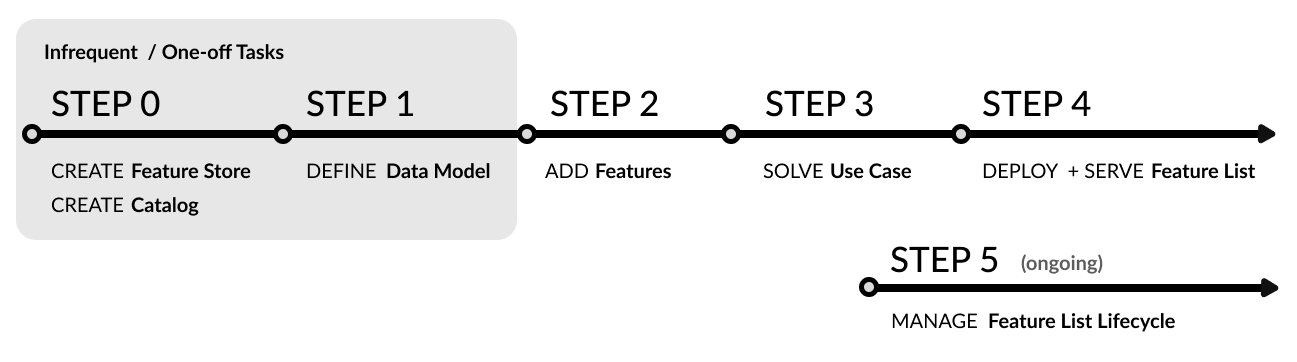
The entire process can be performed using the FeatureByte Python SDK. In addition, you can also connect to the REST API service to serve features during the prediction phase.
Continue reading to learn more about the specific workflows you may need to go through to get the most out of FeatureByte.
STEP 0: Install FeatureByte¶
If FeatureByte is not installed yet, check out the following:
- Installation for setting up the FeatureByte service for different usage scenarios.
- System Architecture for details on the different FeatureByte components.
STEP 0: Create a Feature Store¶
- Ensure you choose any of these supported data warehouses: Snowflake, Databricks, or Spark.
-
Ensure you have the appropriate access permissions:
- read access is required for databases containing the source tables you want to use for feature engineering.
- write access is required for the database that FeatureByte will use as the feature store.
-
Create the feature store by providing the connection details and credentials.
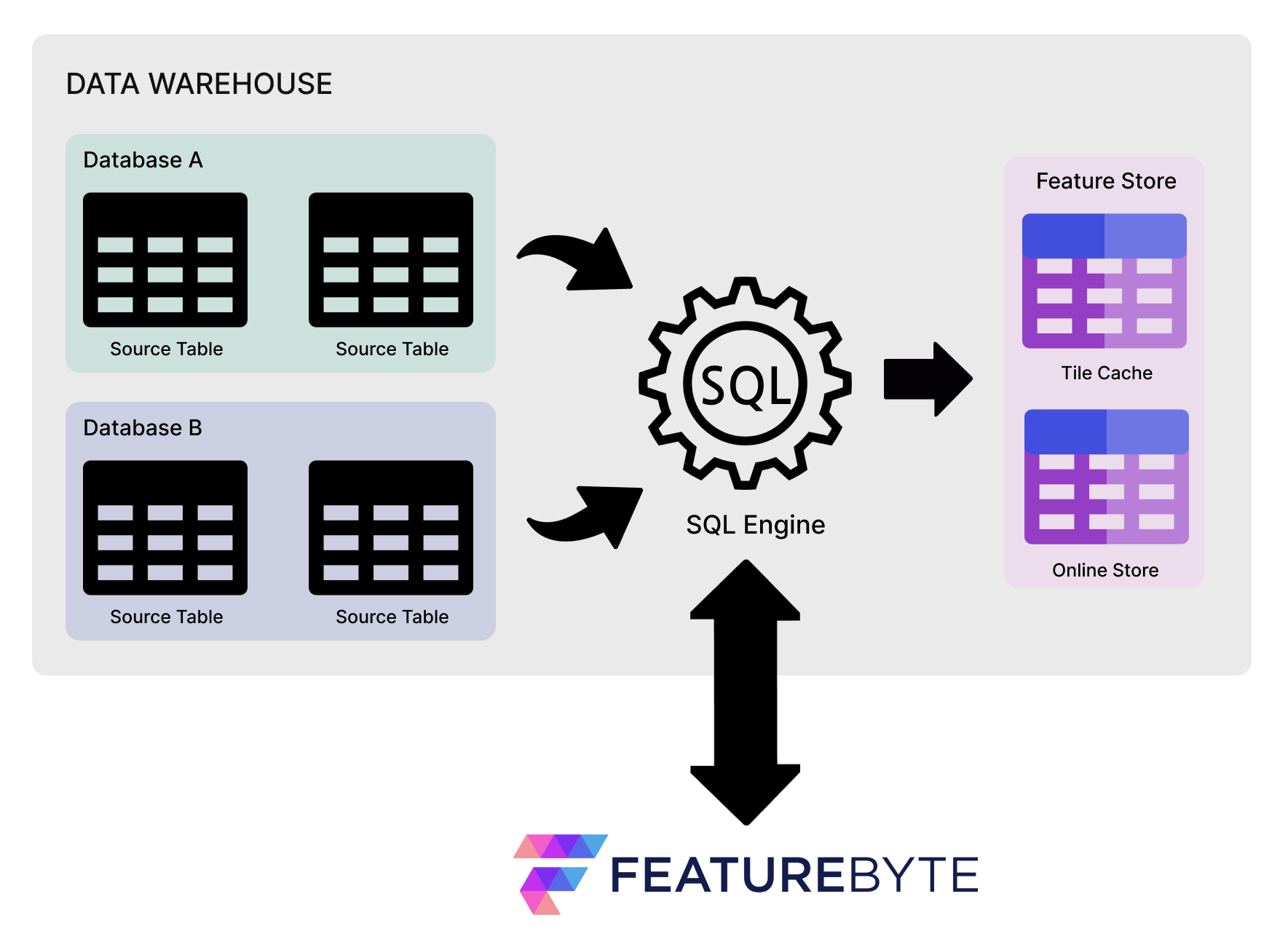
Once the feature store is set up, FeatureByte will utilize your data warehouse as a:
- data source.
- compute engine to leverage its scalability, stability, and efficiency.
- storage of partial aggregates (tiles) and precomputed feature values to support feature serving.
Note
Creating a feature store is a one-time activity for each data warehouse accessible to you.
Refer to Connecting to your Data Warehouse for more details.
Check out our SDK reference for FeatureStore and DataSource.
STEP 0: Create a Catalog¶
- Explore the source tables FeatureByte can read.
- Evaluate if they cover multiple domains.
- Create a catalog for each domain to maintain clarity and easy access to domain-specific metadata.
By using a catalog, you and your team members can:
- share, search, retrieve, and reuse tables, entities, features, feature lists and other core objects required for feature serving.
- and obtain comprehensive information about their properties.
Note
Creating a Catalog is a straightforward but infrequent task.
Get Started with Quick Start End-to-End tutorial.
Check out our SDK reference for SourceTable and Catalog.
STEP 1: Define the Data Model of the catalog¶
- Activate the catalog you want to work with.
- Determine the type of the source tables you want to register. There are four supported types: event table, item table, dimension table and slowly changing dimension table.
- Add the tables to the catalog according to their types.
- Recognize the entities in your data and register them in the catalog.
- Apply tags to columns that represent or reference the entities you have registered. This will facilitate joins and automatically associate features with the corresponding entities.
- Assign default cleaning operations to handle data issues effectively during the feature engineering process.
- For event tables, initialize a default feature job setting configuration to be used by features derived from the table and its associated item table. If your table maintains a record creation timestamp, this is automatically done by FeatureByte based on an analysis of the table data's freshness and availability. This ensures:
- uniformity among features created by various team members
- consistency between historical requests and online and batch serving.
Note
Defining the Data Model is an infrequent but essential task to ensure good feature engineering practices.
Get Started with Deep Dive Data Modeling tutorial.
Check out the SDK reference for Entity, Table and TableColumn.
STEP 2: Add Features to the Catalog¶
-
Generate views from the tables in the catalog to manipulate data. Views are not loaded into memory like Pandas DataFrames. Instead, they are materialized when needed for exploratory data analysis or feature materialization.
-
Enhance your views by adding new columns either through joins or by transforming columns using existing columns.
-
Develop features using the views you created. There are three primary methods for feature creation:
-
Optionally, you can transform existing features to create new features.
Note
Creating a feature is a frequent task. However, once a feature is created and shared, it can be reused effortlessly.
Get Started with ‘Quick Start Feature Engineering’ tutorial and 'Deep Dive Feature Engineering’ tutorial.
Check out the SDK reference for View, ViewColumn and Feature.
STEP 3: Solve a Use Case¶
- Identify the target and the entity (or the tuple of entities) that define your use case.
- Create, upload, or retrieve observation sets from the catalog for training and testing. The observation set combines key values of your use case entity and past points-in-time you want to learn from.
- Construct feature lists using features from the catalog and create new features, if needed. Add them to the catalog for future use.
- Obtain training and test data using historical feature requests based on your observation sets.
- Train and test ML models using created training and test data.
- If satisfied with one feature list's accuracy, select it as a candidate for deployment.
Note
Creating feature lists and training data is a frequent task that is essential to get the best from Machine Learning models. FeatureByte eliminates the constraints of traditional ad-hoc pipelines in terms of scalability, feature complexity, and feature freshness. With FeatureByte, you can work with large datasets, inventive features, and a broad range of points-in-time, ultimately leading to improved accuracy in your Machine Learning models.
Get Started with Quick Start Model Training, Quick Start Reusing Features and Deep Dive Materializing Features tutorials.
Check out the SDK reference for FeatureList, ObservationTable and HistoricalFeatureTable.
STEP 4: Deploy and Serve a Feature List¶
- Review the feature definition file of features in your feature list that are not production-ready yet.
- Label them as production-ready to enable the deployment of the feature list.
- Deploy the feature list. Once a feature list is deployed, the FeatureByte Service automatically orchestrates the pre-computation of feature values and stores them in an online feature store for online and batch serving.
- Use the REST API service to retrieve feature values from the online feature store for online serving or use the SDK to retrieve batch of feature values from the online feature store for batch serving.
Note
With FeatureByte, deploying and serving Feature Lists becomes a frequent task thanks to the removal of the complexity of building and maintaining separate production pipelines.
Get Started with Deep Dive Materializing Features tutorial.
Check out the SDK reference for Deployment, BatchRequestTable and BatchFeatureTable.
STEP 5: Manage the Life Cycle of your Feature List¶
- Review the feature job status report to see recent activity for scheduled jobs related to your feature list.
- If errors in the feature jobs are due to insufficient compute capacity, consider upsizing your instances.
- If you encounter unexpected data changes, create new feature versions and update your feature lists with the appropriate feature job setting or cleaning operations.
- If online and batch serving becomes unnecessary, disable deployment without affecting historical request serving, unlike some feature stores' log and wait method.
Note
Get Started with Quick Start Feature Management tutorial.