13. Unleash Your Creativity
In this final section of our tutorial series, we'll demonstrate three powerful ways FeatureByte enhances your ability to perform advanced feature engineering.
- Edit features suggested by FeatureByte Copilot.
- Use FeatureByte's filtering capability to unearth features that concentrate on specific subsets of your data.
- Make FeatureByte Copilot use your own User Defined Function to leverage the power of transformer models and generate more advanced features from text or other data.
1. Edit Features suggested by FeatureByte Copilot¶
FeatureByte's Copilot provides suggested features that can be further customized within our SDK. We will guide you through the process of downloading a feature notebook, editing its code, and adding the newly customized feature to your catalog.
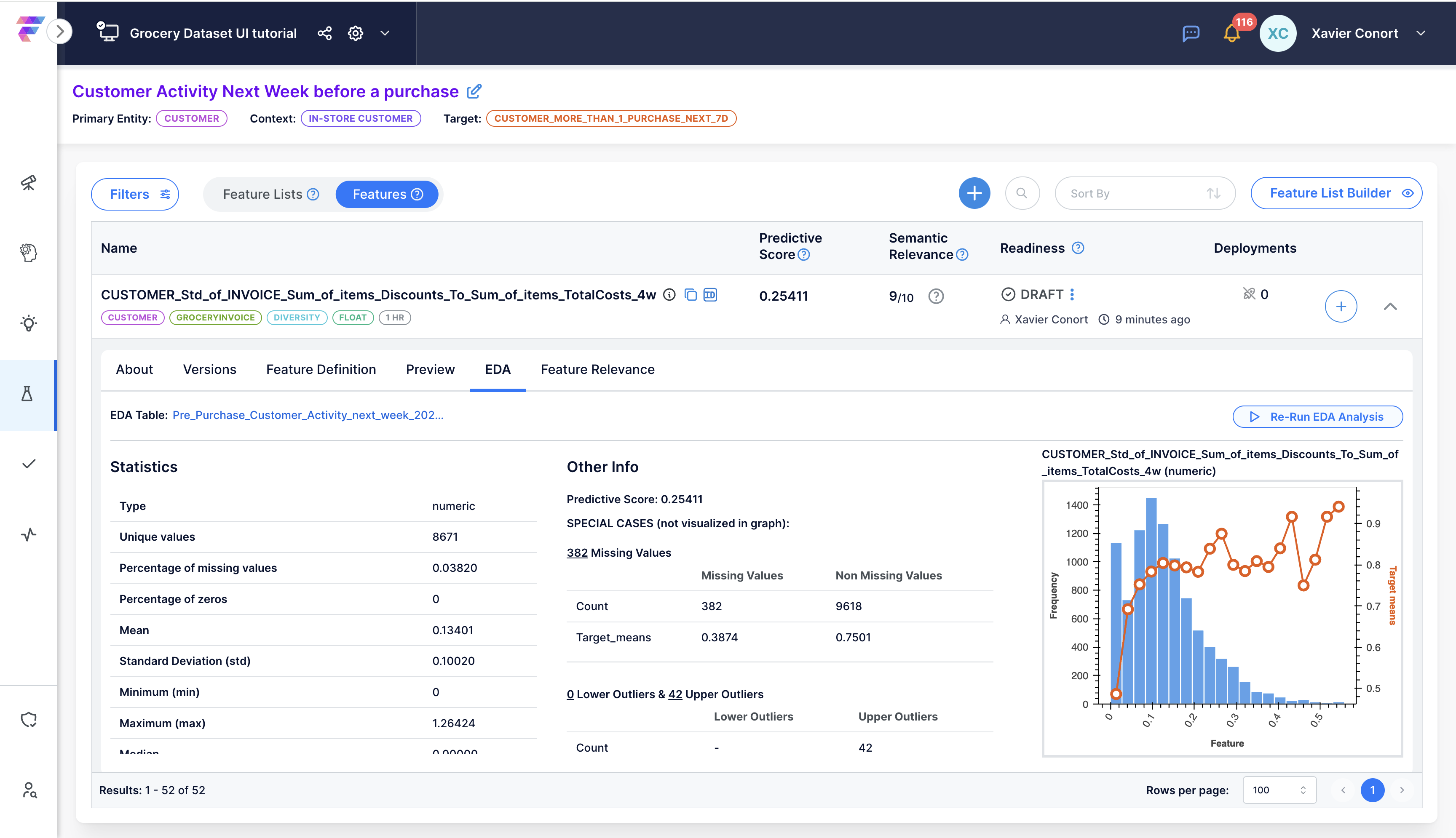
For example, you will learn how to modify the suggested feature CUSTOMER_Max_of_INVOICE_Sum_of_items_Discounts_To_Sum_of_items_TotalCosts.
This feature calculates the ratio of discounts to total costs for each invoice, then finds the maximum ratio for each customer over the past four weeks.
Screenshots guide you through each step, from downloading to modifying and running the notebook, and analyzing the feature in the Feature Catalog.
Step 1: Select a Feature and Download its Notebook¶
Let's select the feature suggested by Copilot in Feature Ideation.
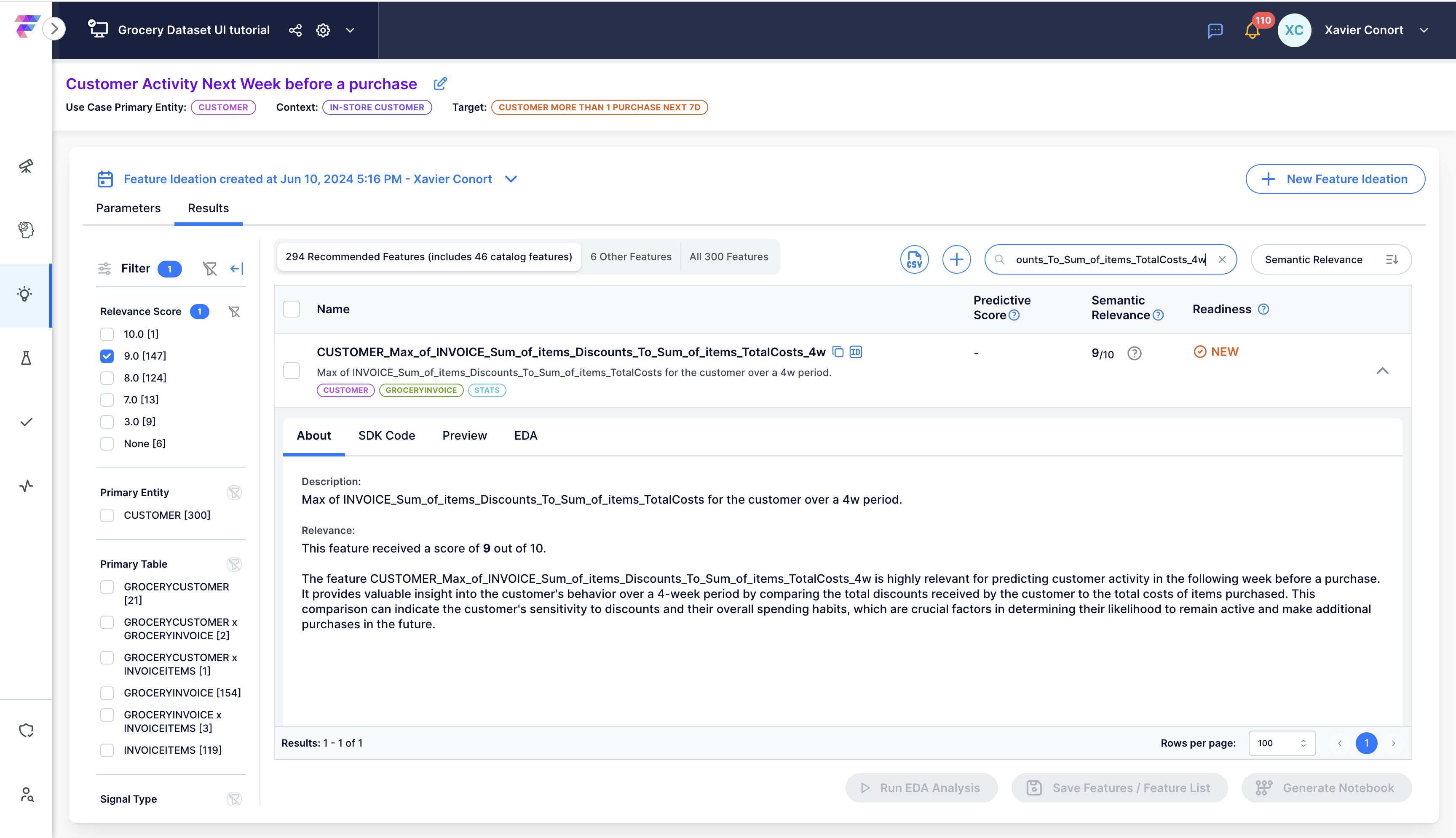
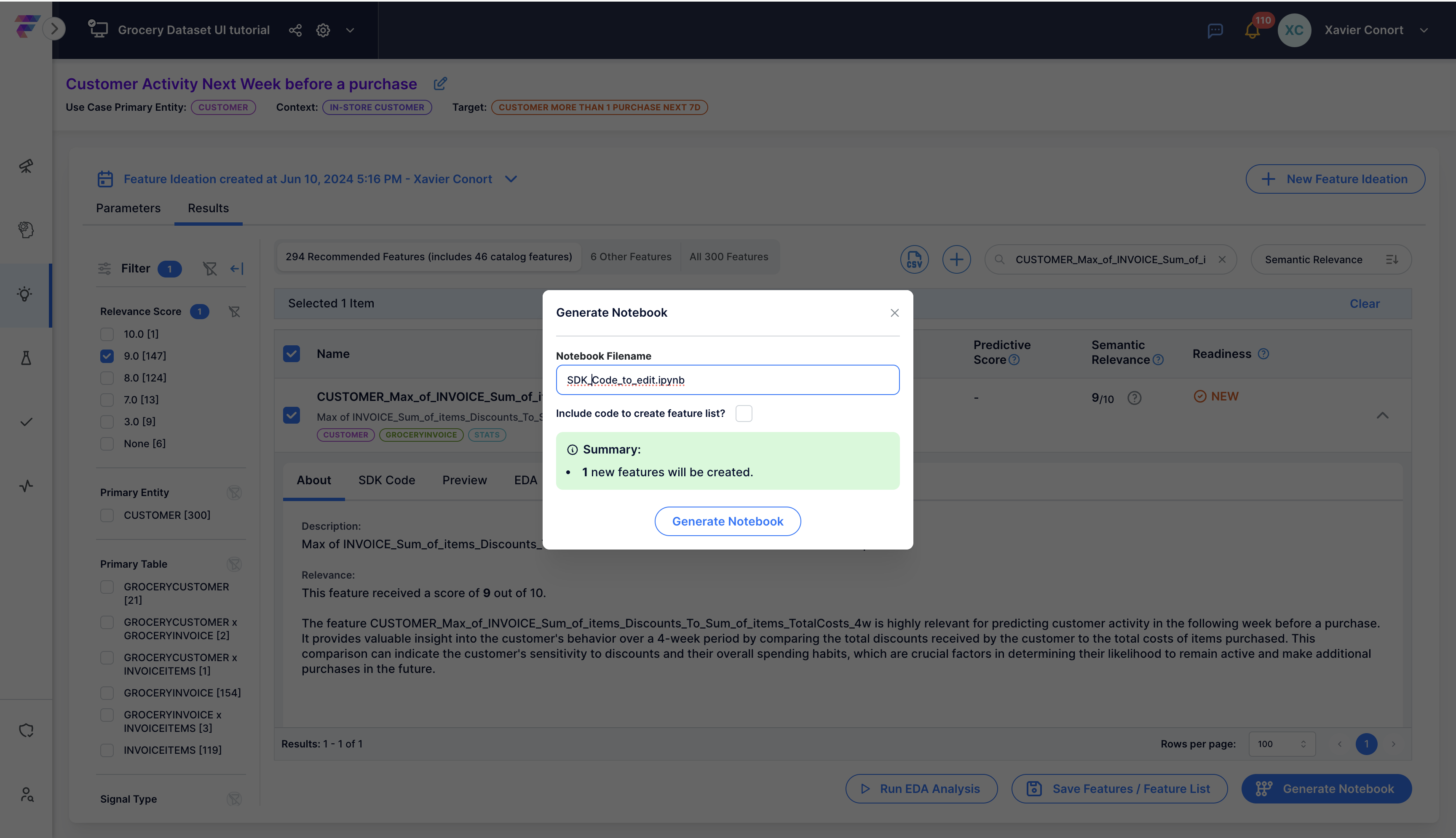
Download the notebook by selecting the feature and clicking ![]() .
.
Step 2: Explore the Notebook¶
Explore the Feature SDK code in the notebook.
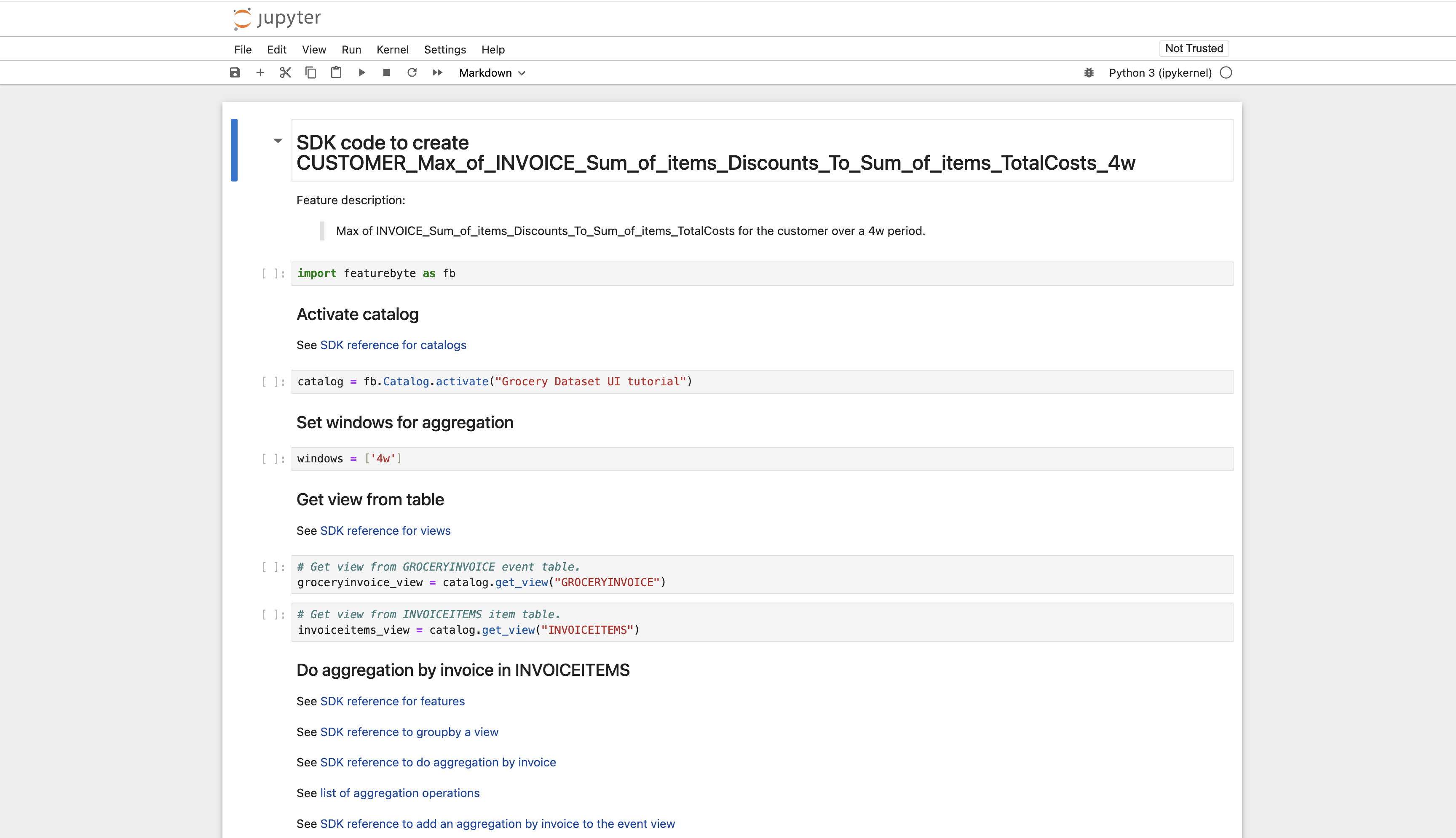
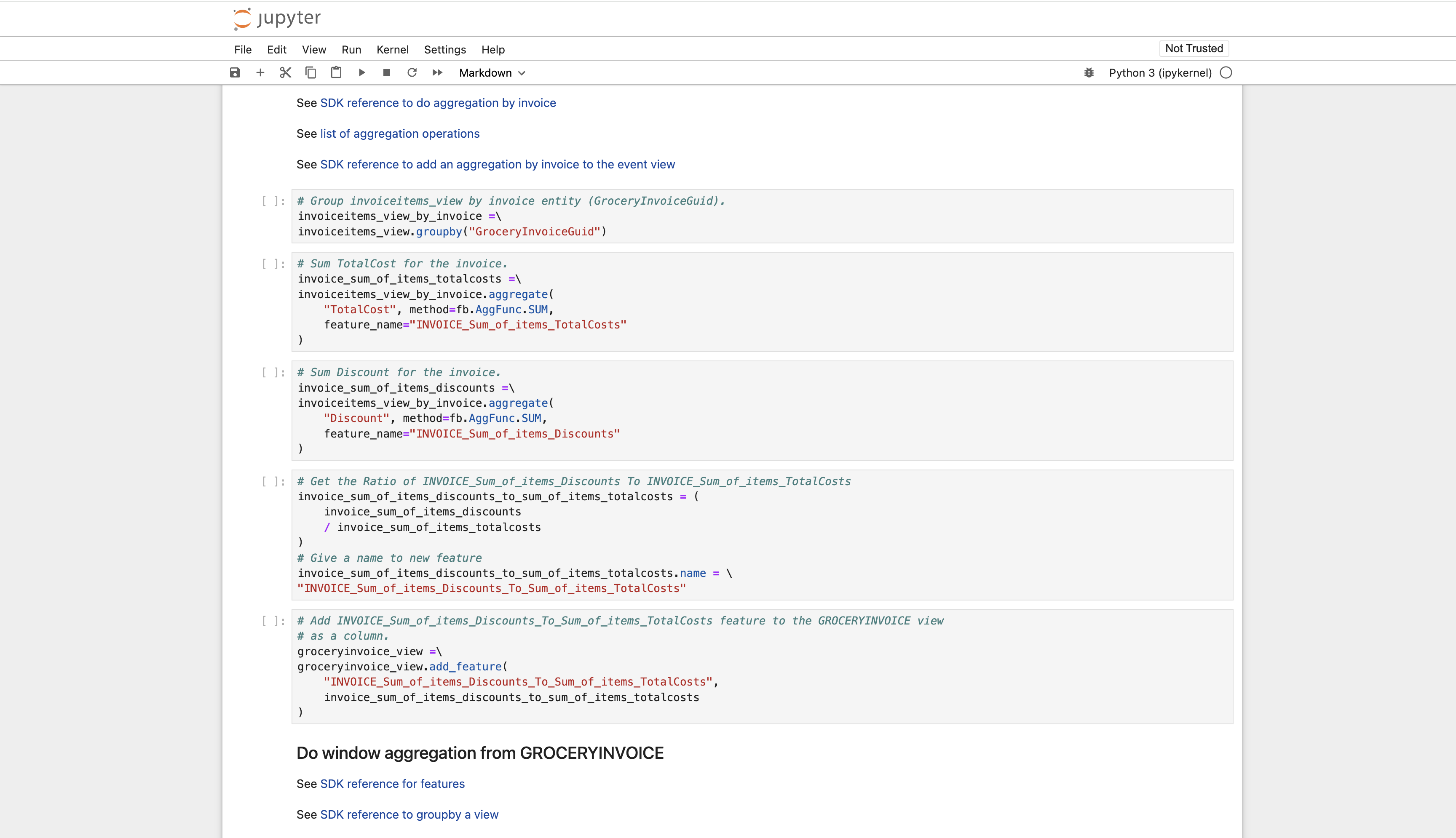
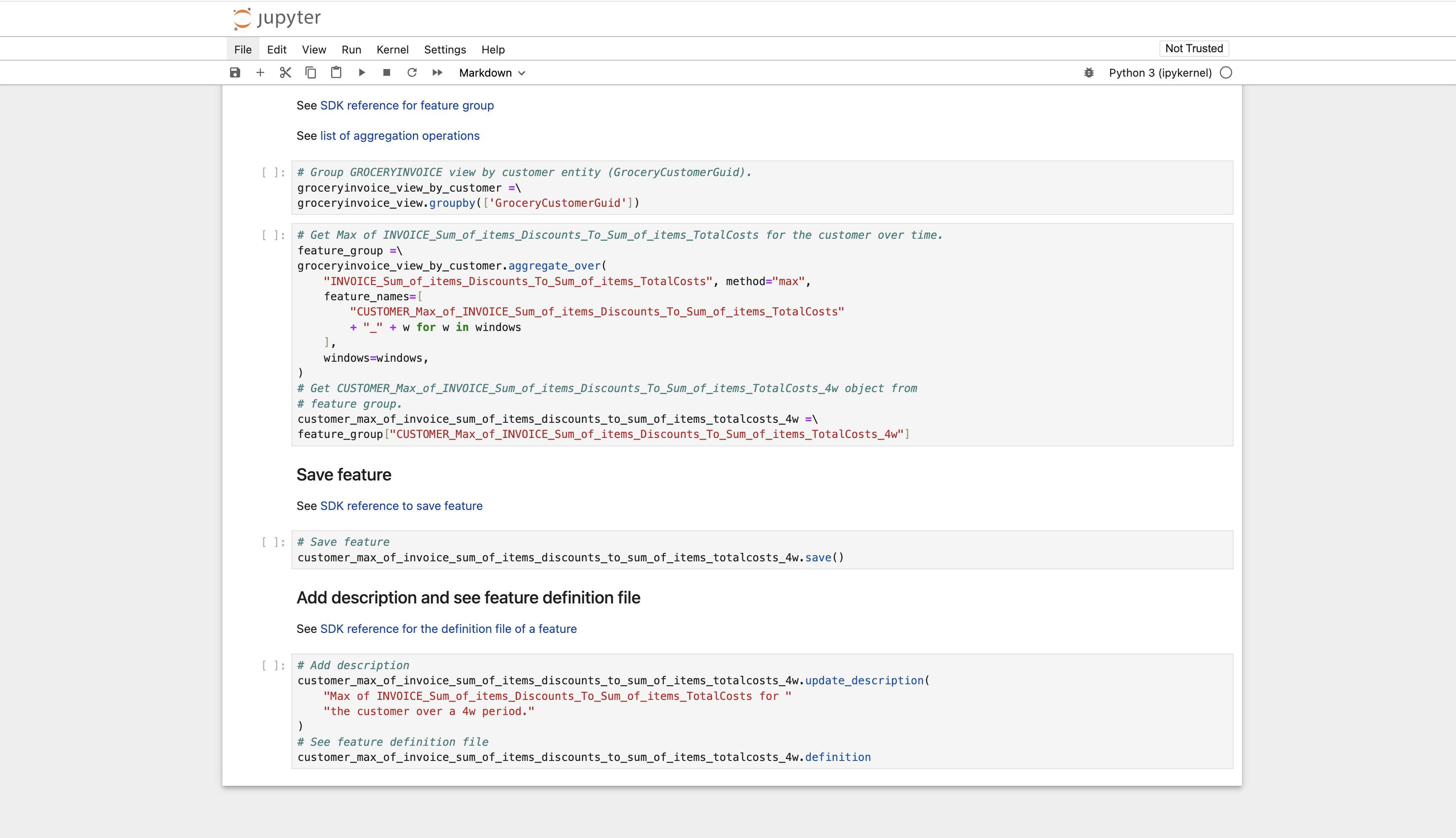
Step 3: Edit the Notebook to Create a New Feature¶
Edit the feature calculation from maximum to standard deviation.
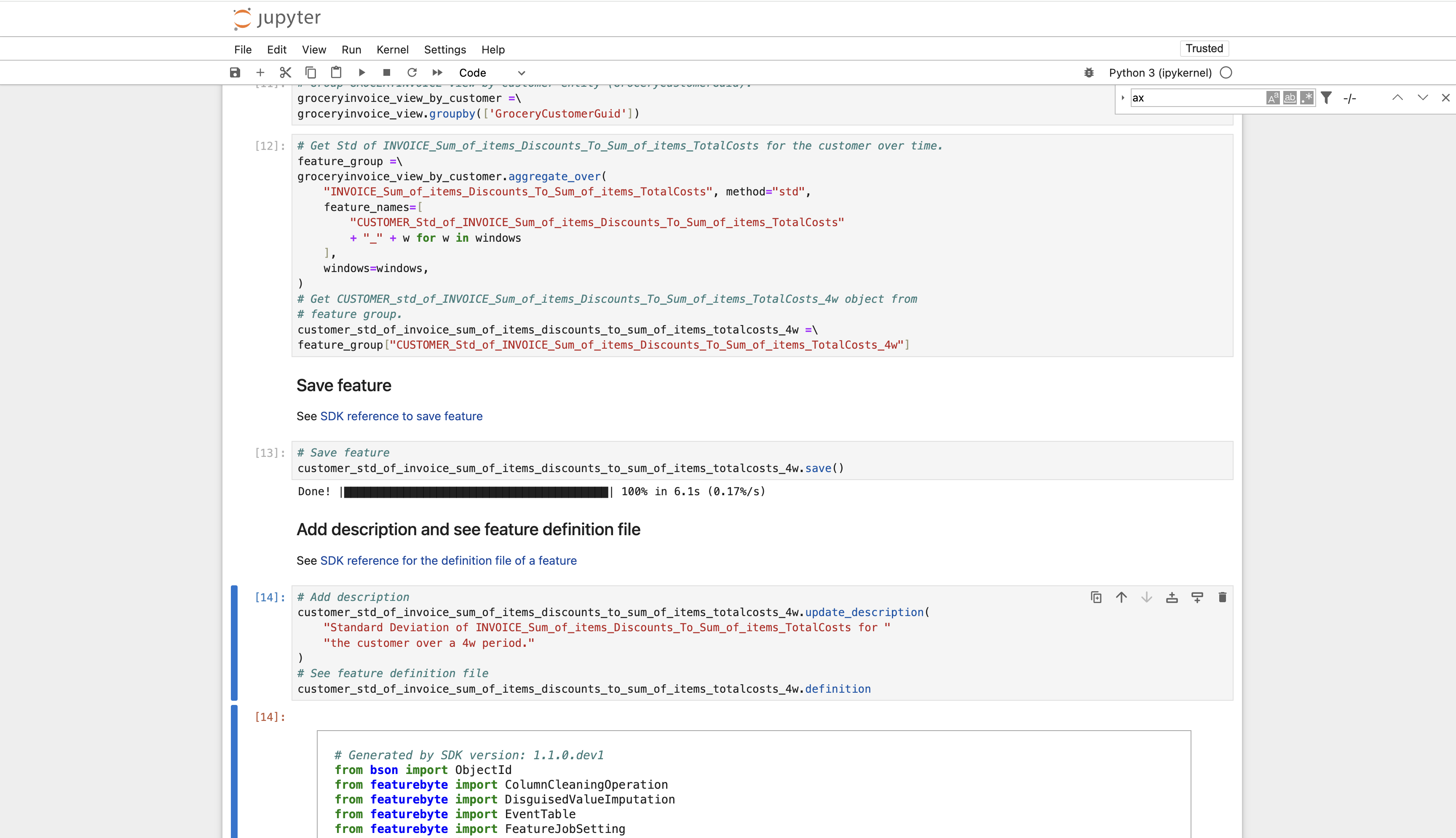
Step 4: Add New Feature to the Catalog and Analyze it¶
Run the notebook to add the new feature to the Feature Catalog. Analyze the new feature's semantic relevanceby clicking ![]() .
.
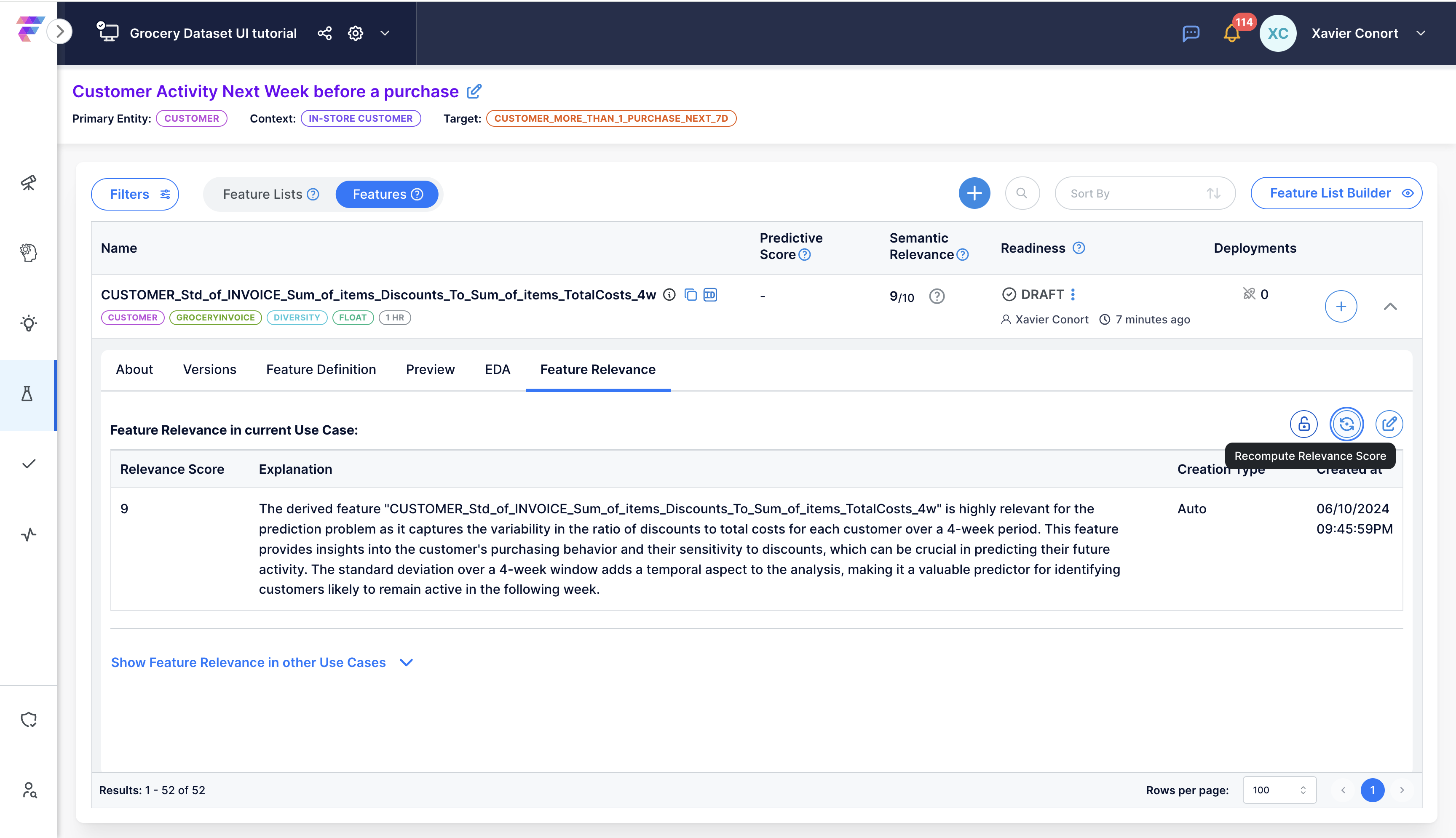
You can also run EDA and check the feature's predictive power for the use case.
2. Discover New Features with Filtering¶
Uncover new features by applying filters to specific data subsets. This section demonstrates starting a new feature ideation session with a focus on the ProductGroup column. It involves:
- Adding filters to narrow down the data.
- Selecting relevant product groups such as staple foods and dairy.
- Considering group suggestions for broader categories, like alcoholic items, and refining your selections.
- Using the Copilot to suggest and evaluate the semantic relevance of these filters.
Illustrative screenshots will show you how to navigate the filter configuration and selection process.
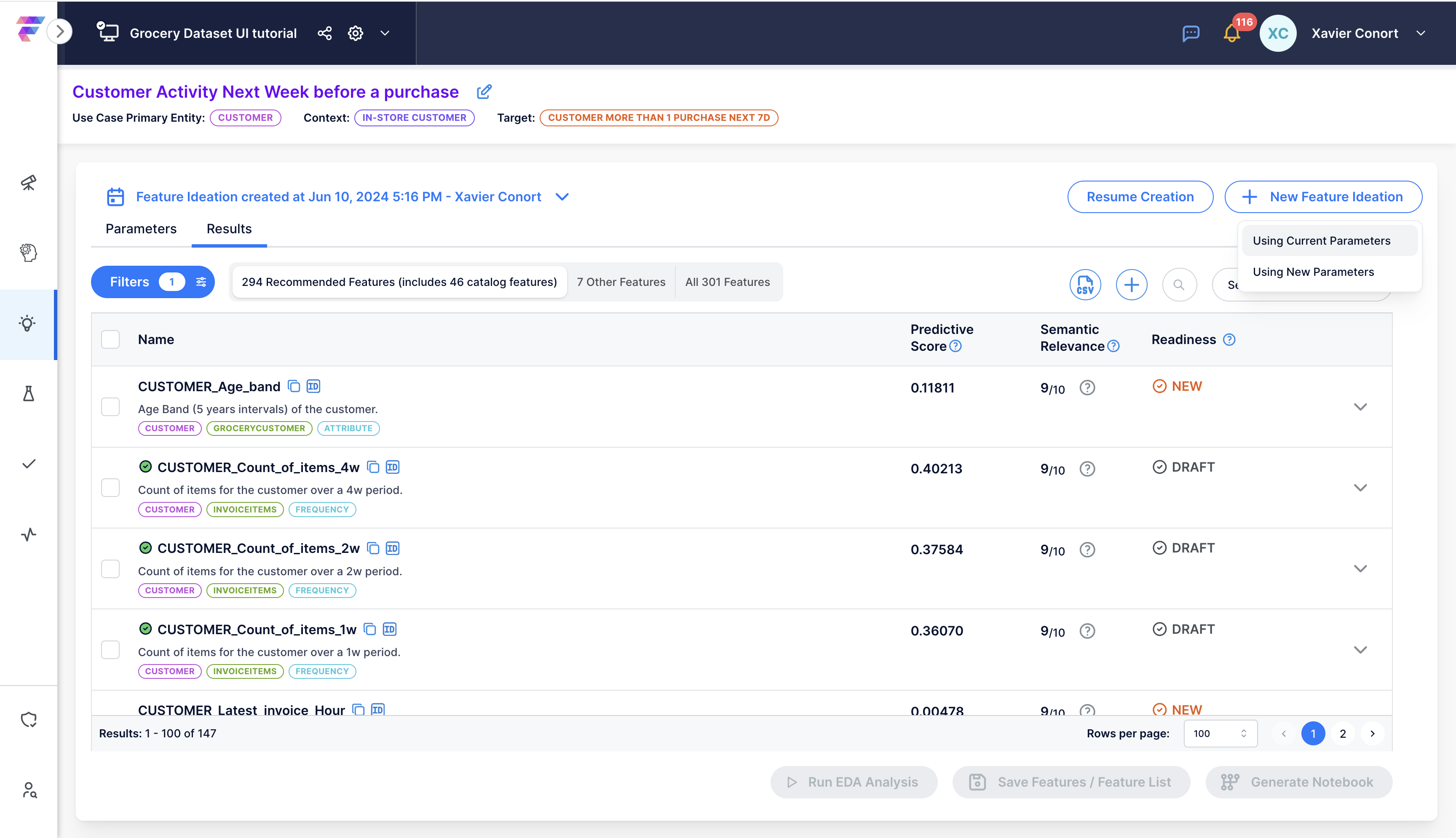
Step 1: Start a New Ideation¶
Start a new ideation session where we will configure a new filter by clicking ![]() .
.
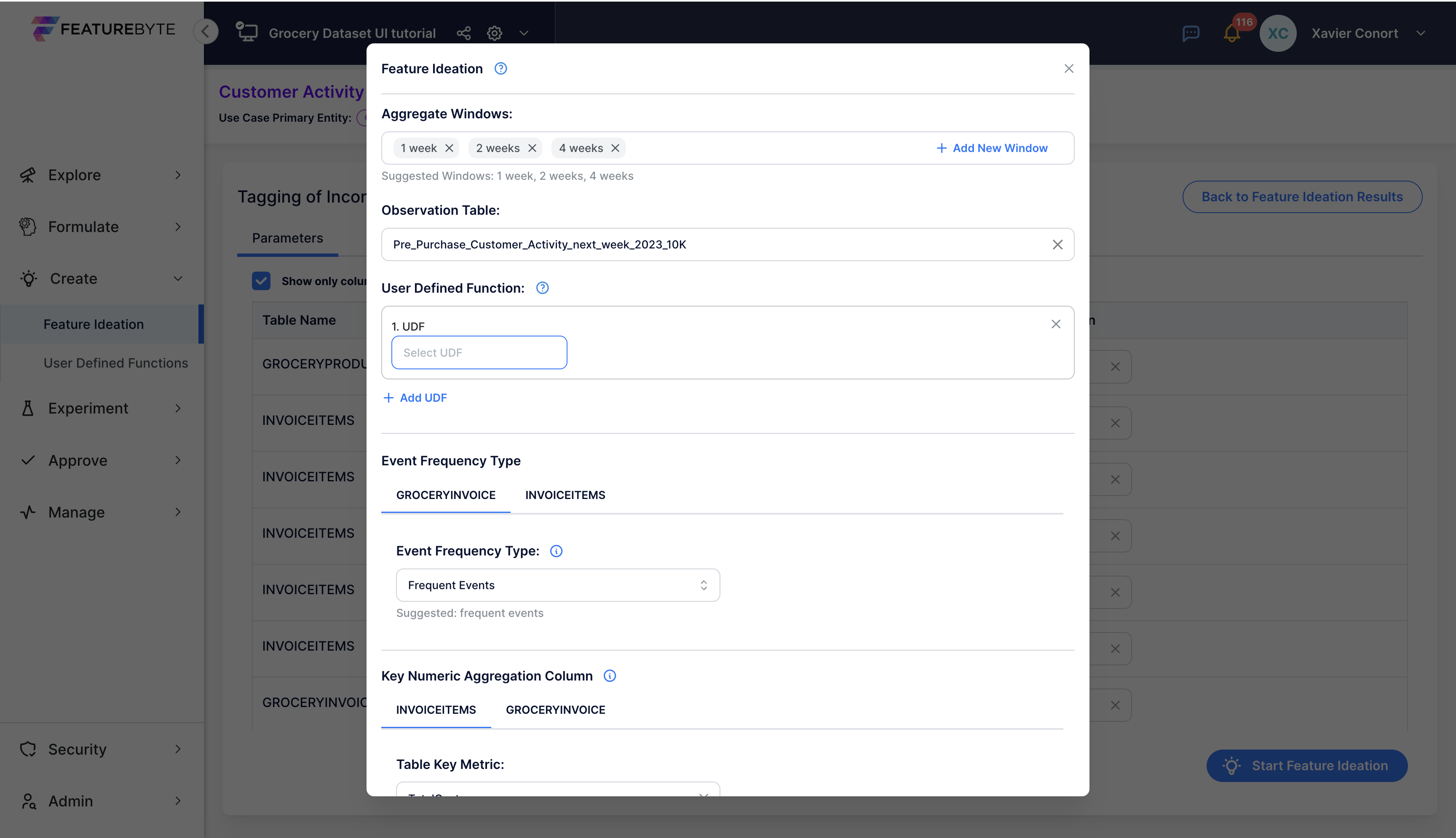
In the Feature Ideation Configuration, scroll down to the Filters section.
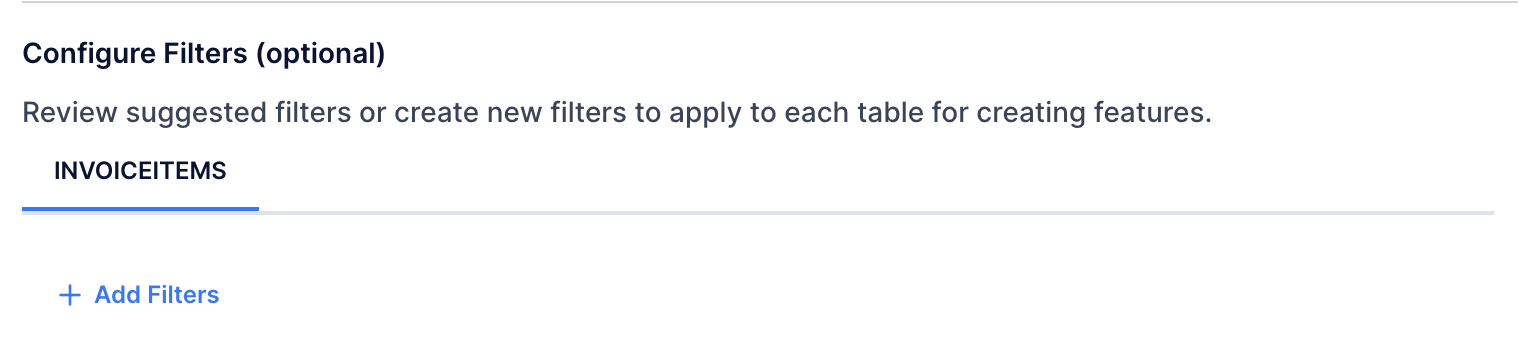
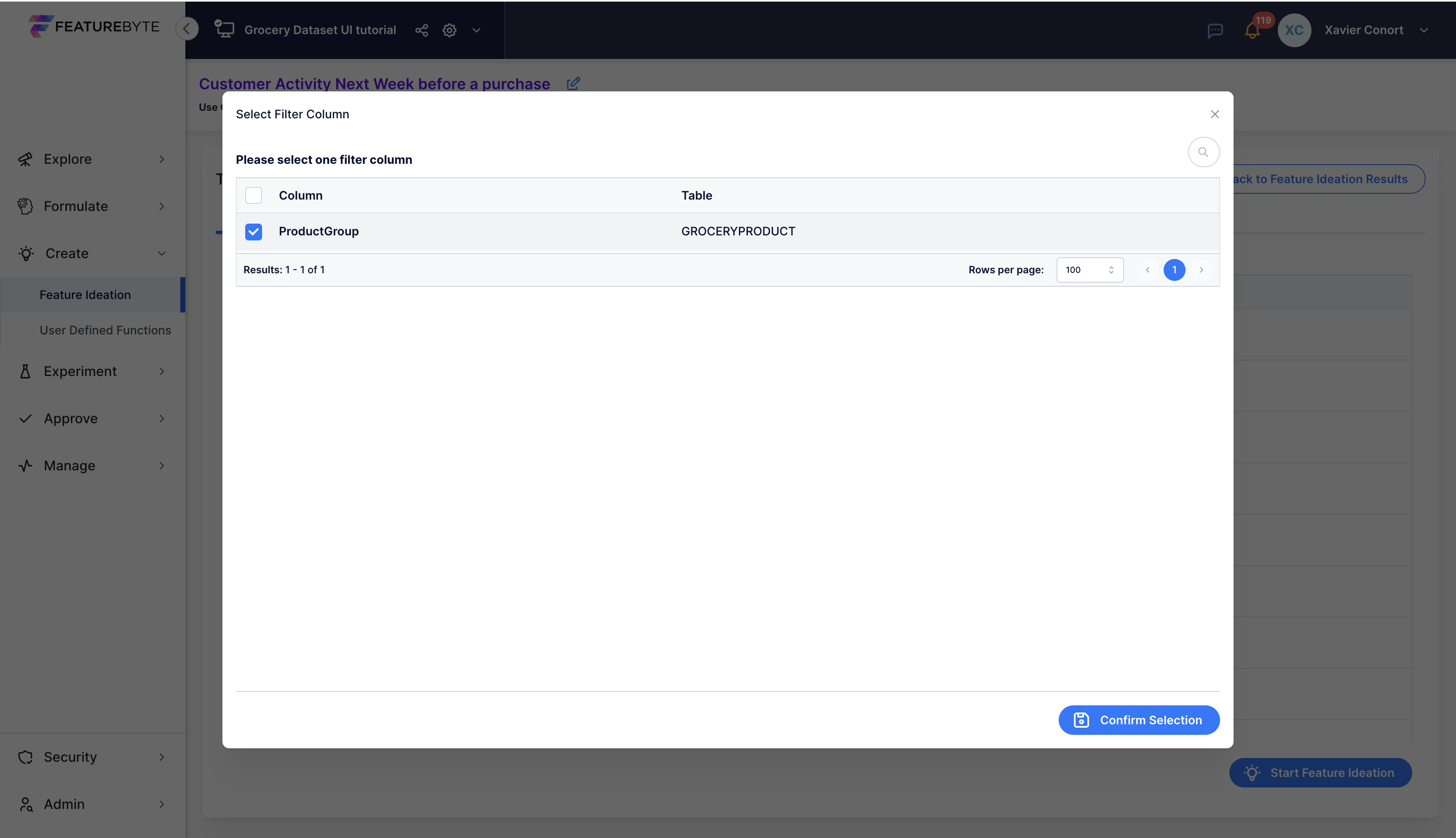
Step 2: Choose Column for the Filter¶
Click 'Add Filters' for the INVOICEITEMS table.
Select 'ProductGroup' as the column to use for our new filter.
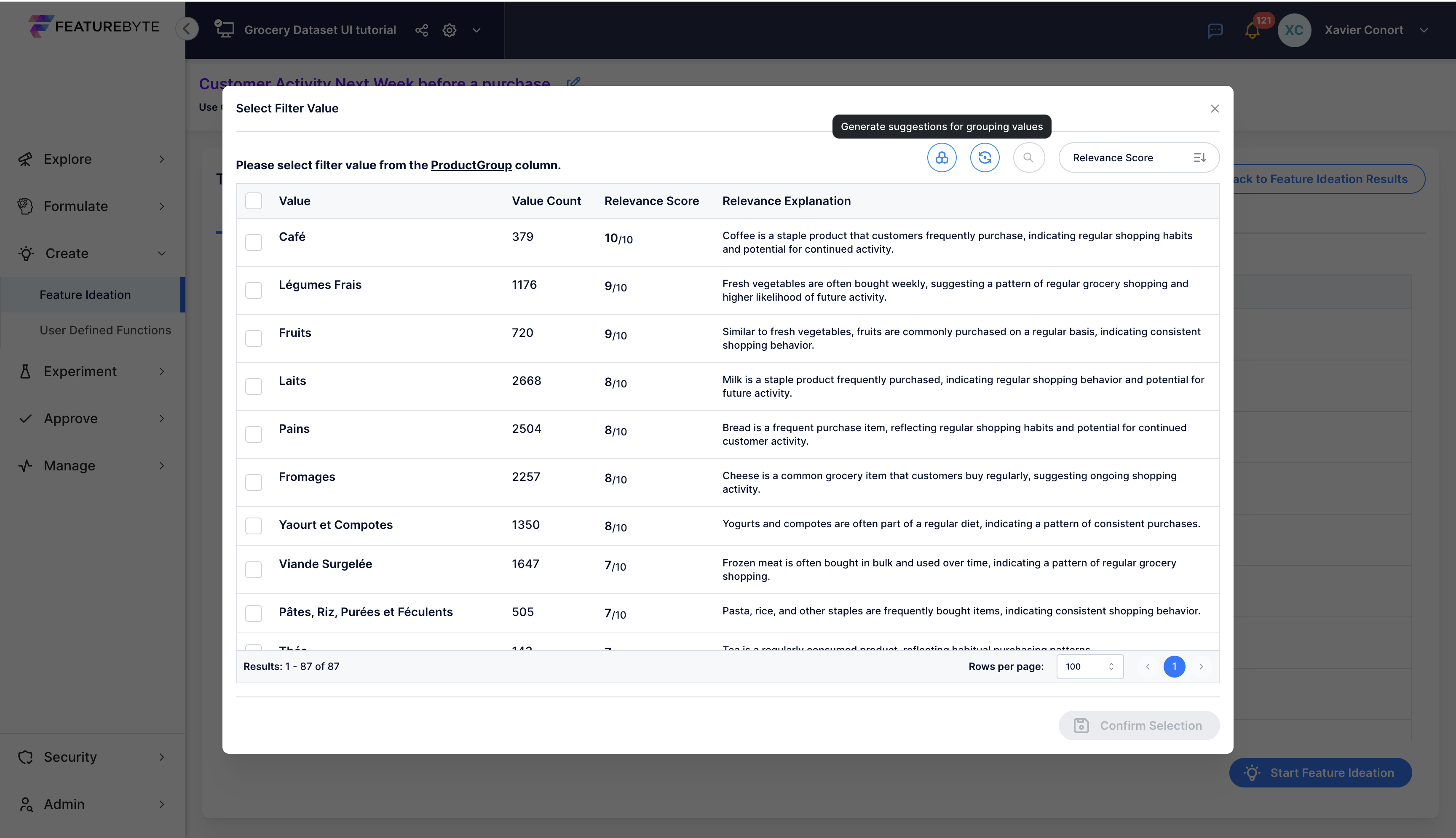
Step 3: Get Suggestions for Column Individual Values¶
Click on ![]() to identify the top 25 most semantically relevant ProductGroup values for our use case to predict a grocery customer's activity next week.
to identify the top 25 most semantically relevant ProductGroup values for our use case to predict a grocery customer's activity next week.
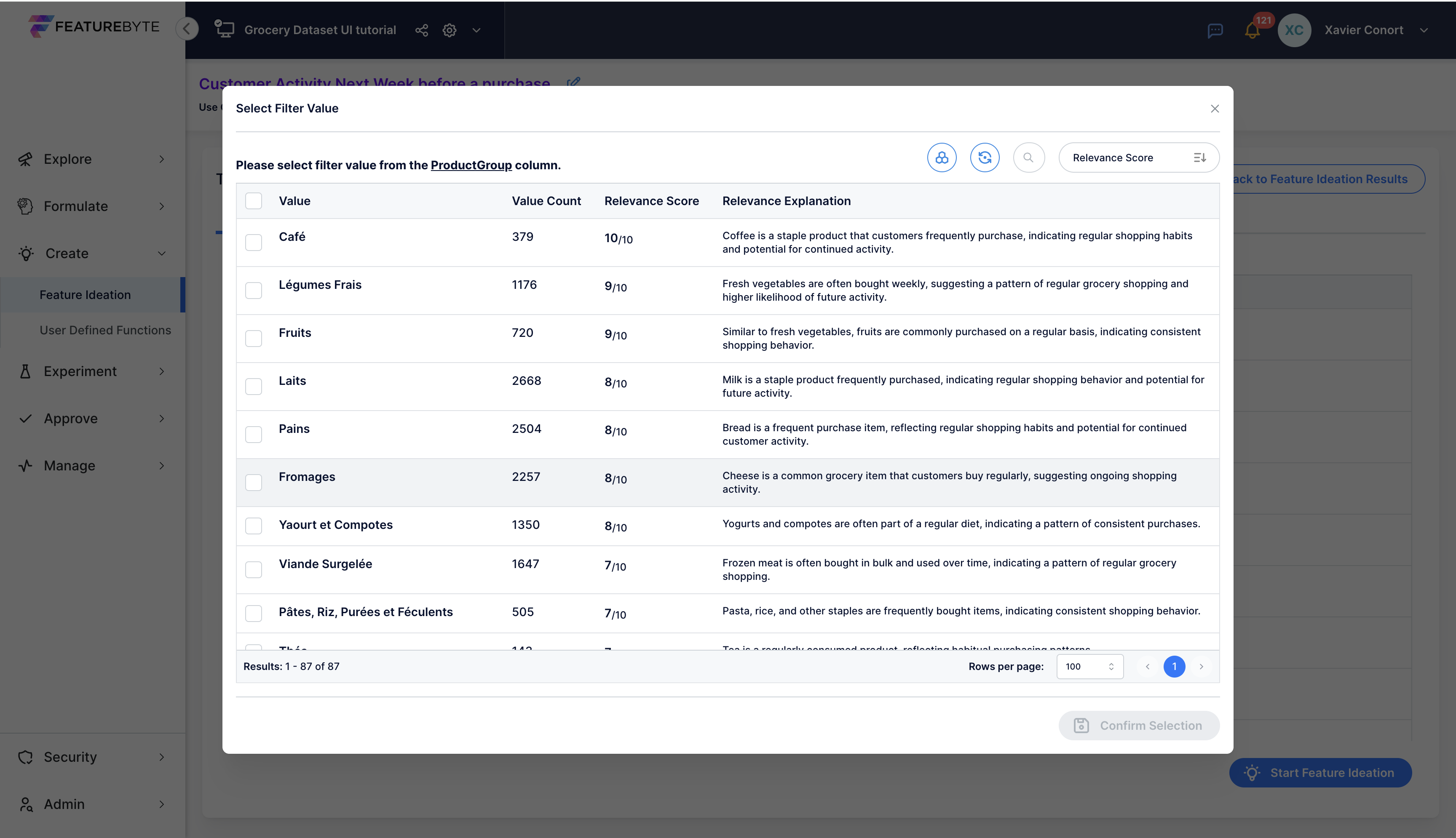
Most relevant ProductGroup values belong to staple foods, dairy, and other fresh products.
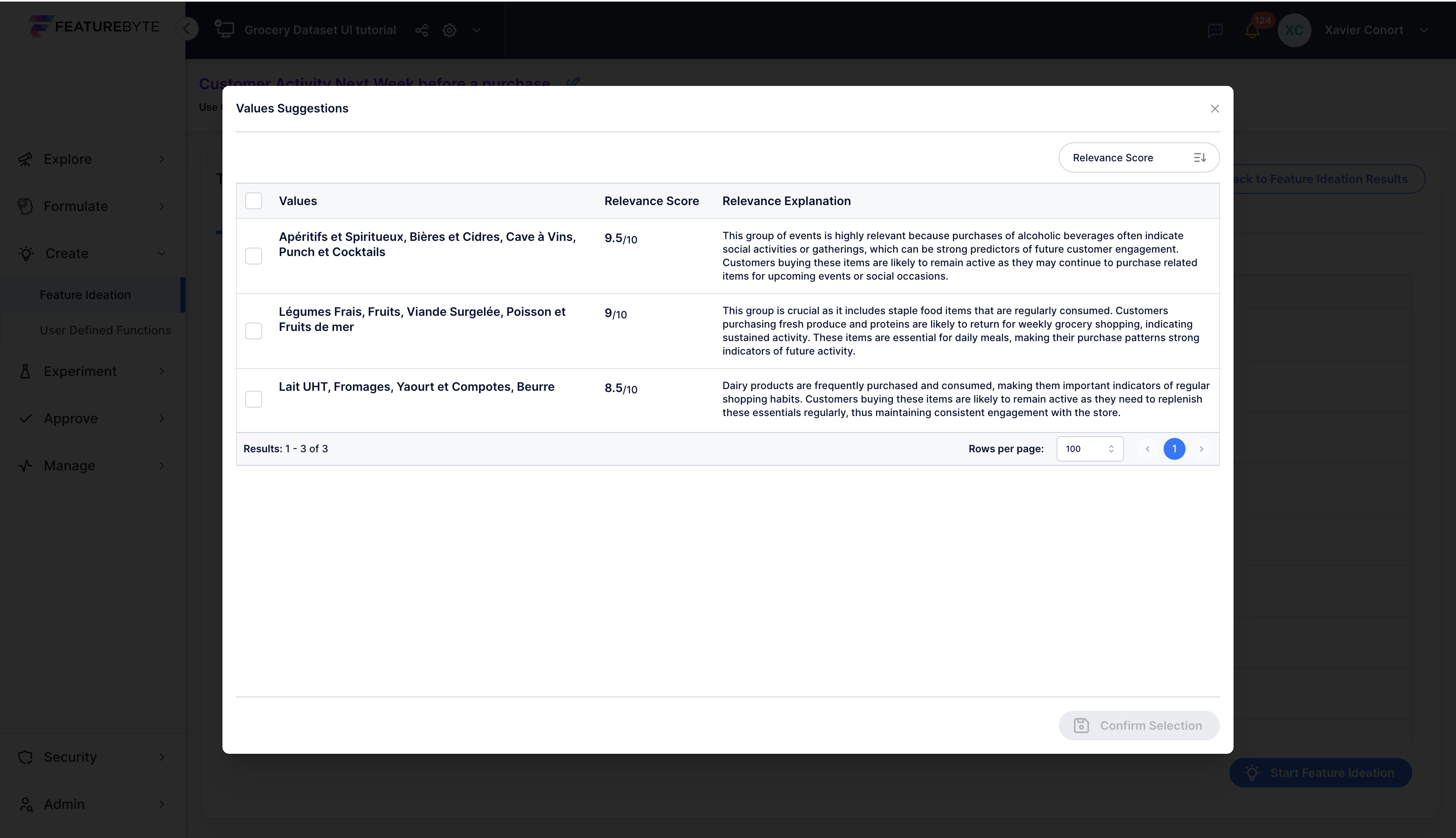
Step 4: Get Suggestions to Group Column values¶
To group these values, click on ![]() to identify the most relevant groups for our use case.
to identify the most relevant groups for our use case.
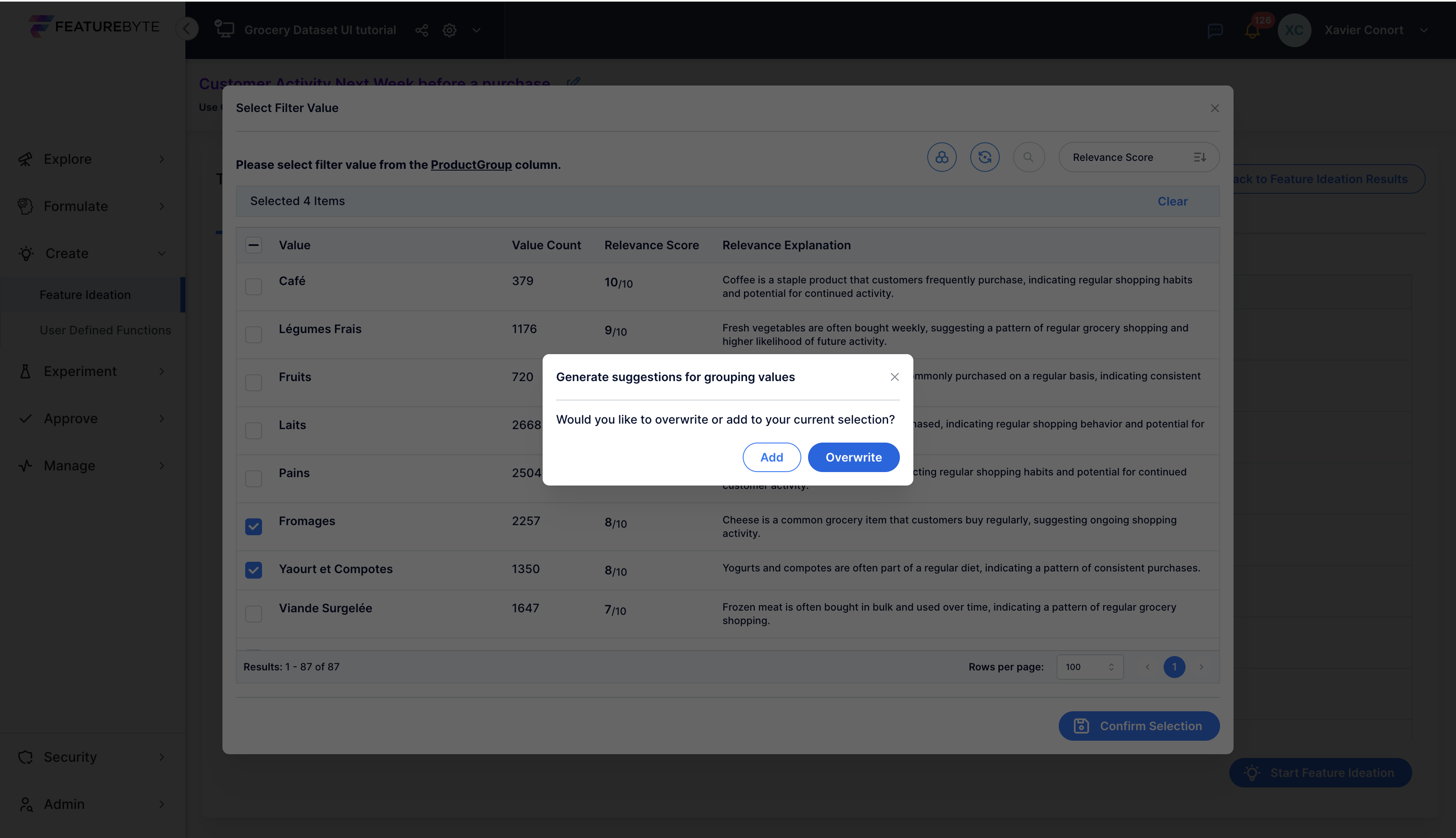
A group of alcoholic items appears first. Let's select another group, the staple food group suggested.
If you had selected items before, confirm whether you want to overwrite this prior selection.
Step 5: Finalize Your New Filter Settings¶
Confirm your final selection.
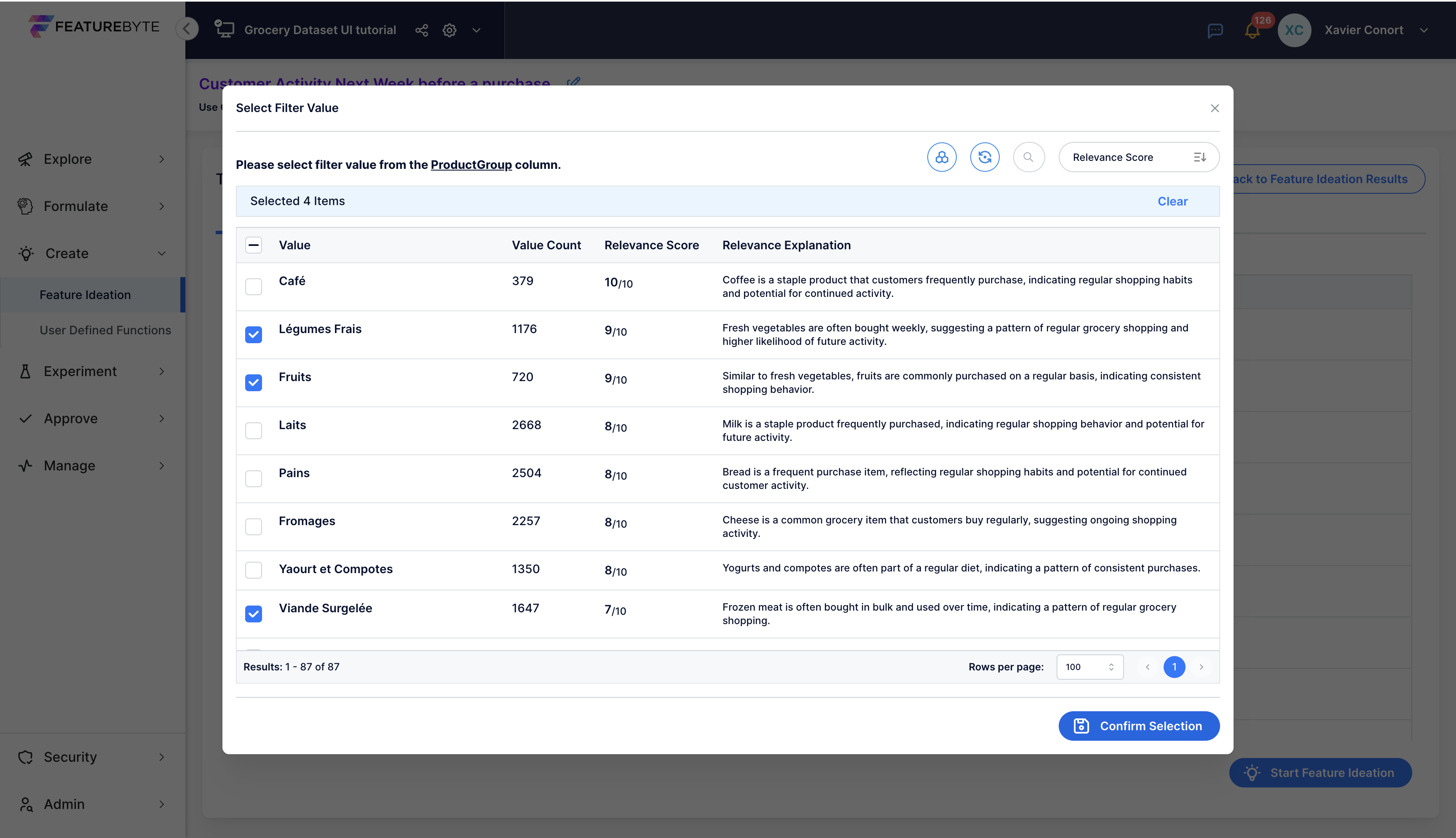
Optionally, provide an alias for the condition.
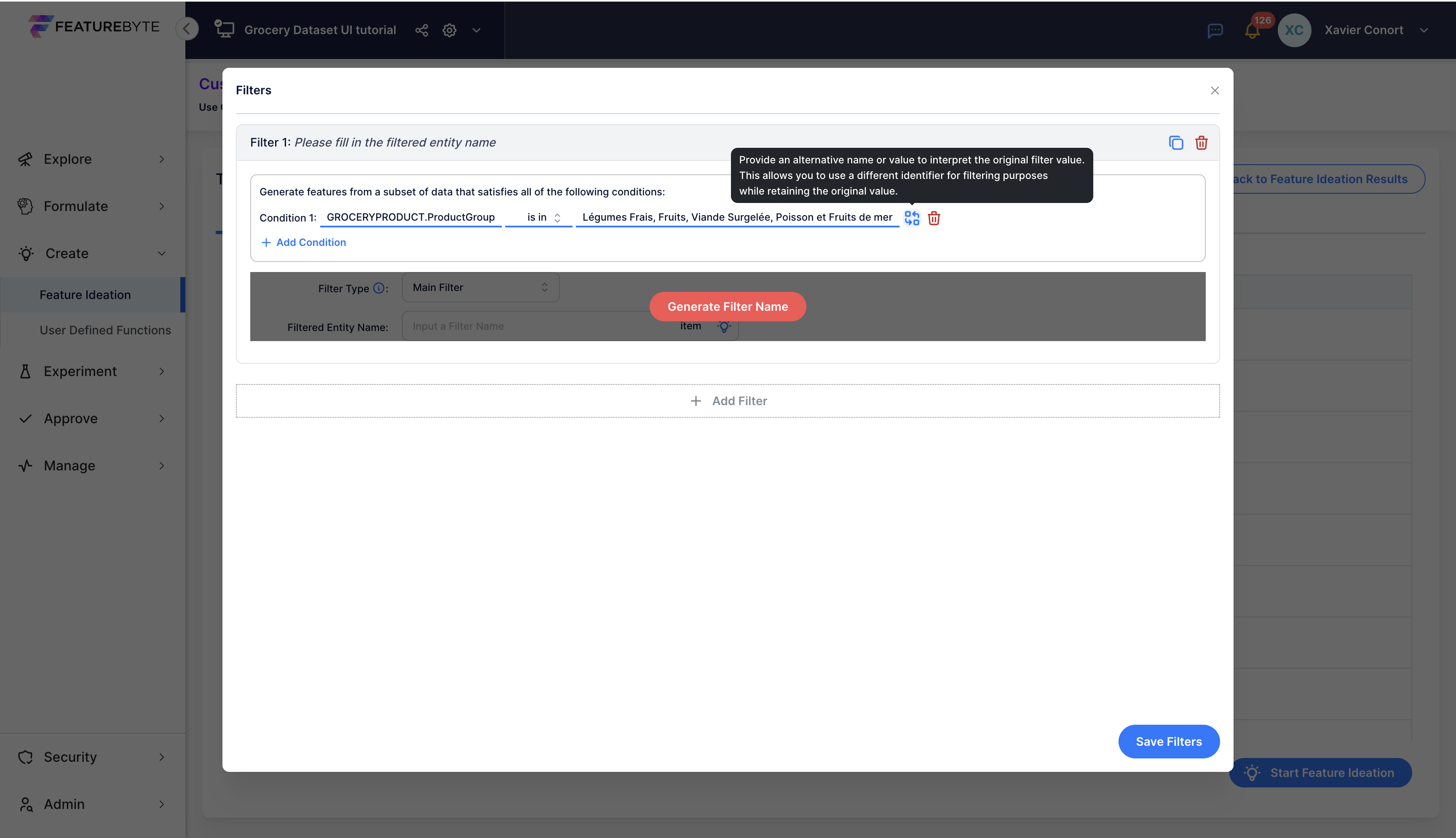
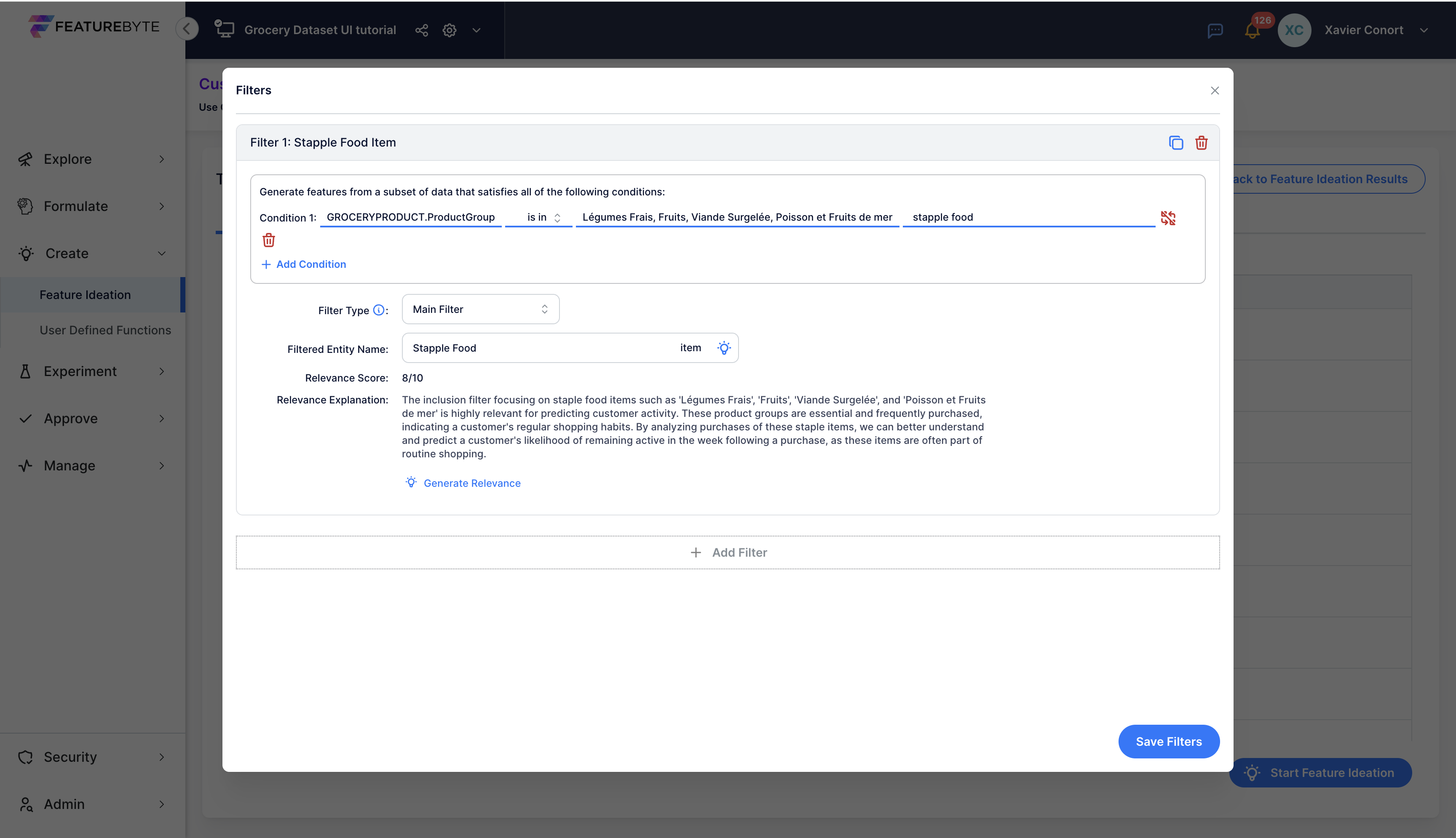
Copilot will suggest a name for this filter and evaluate its semantic relevance.
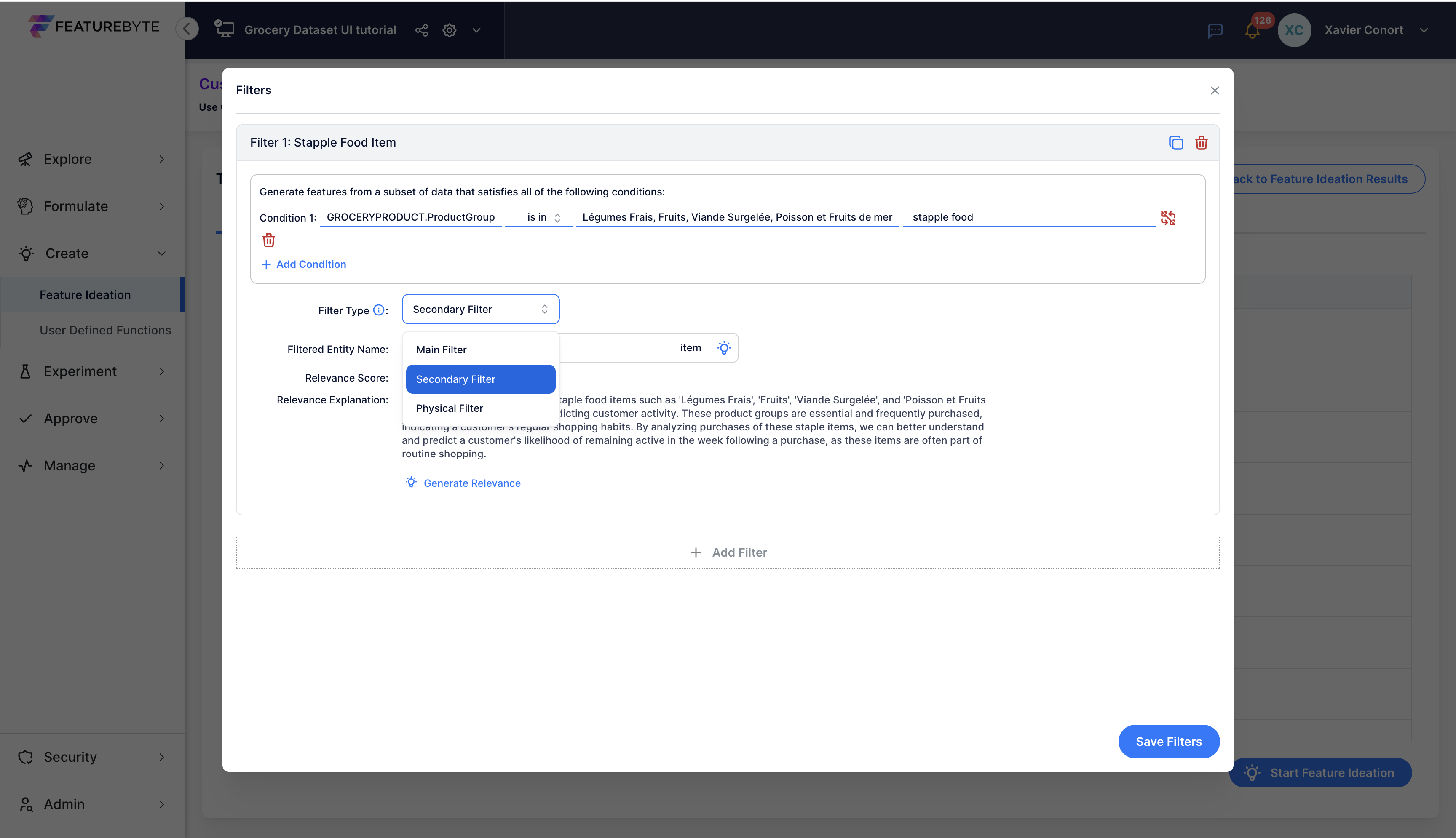
You can change the filter type to secondary filter if you want only simple features to be produced for this filter.
You can specify whether features using the non filtered table should be also produced.
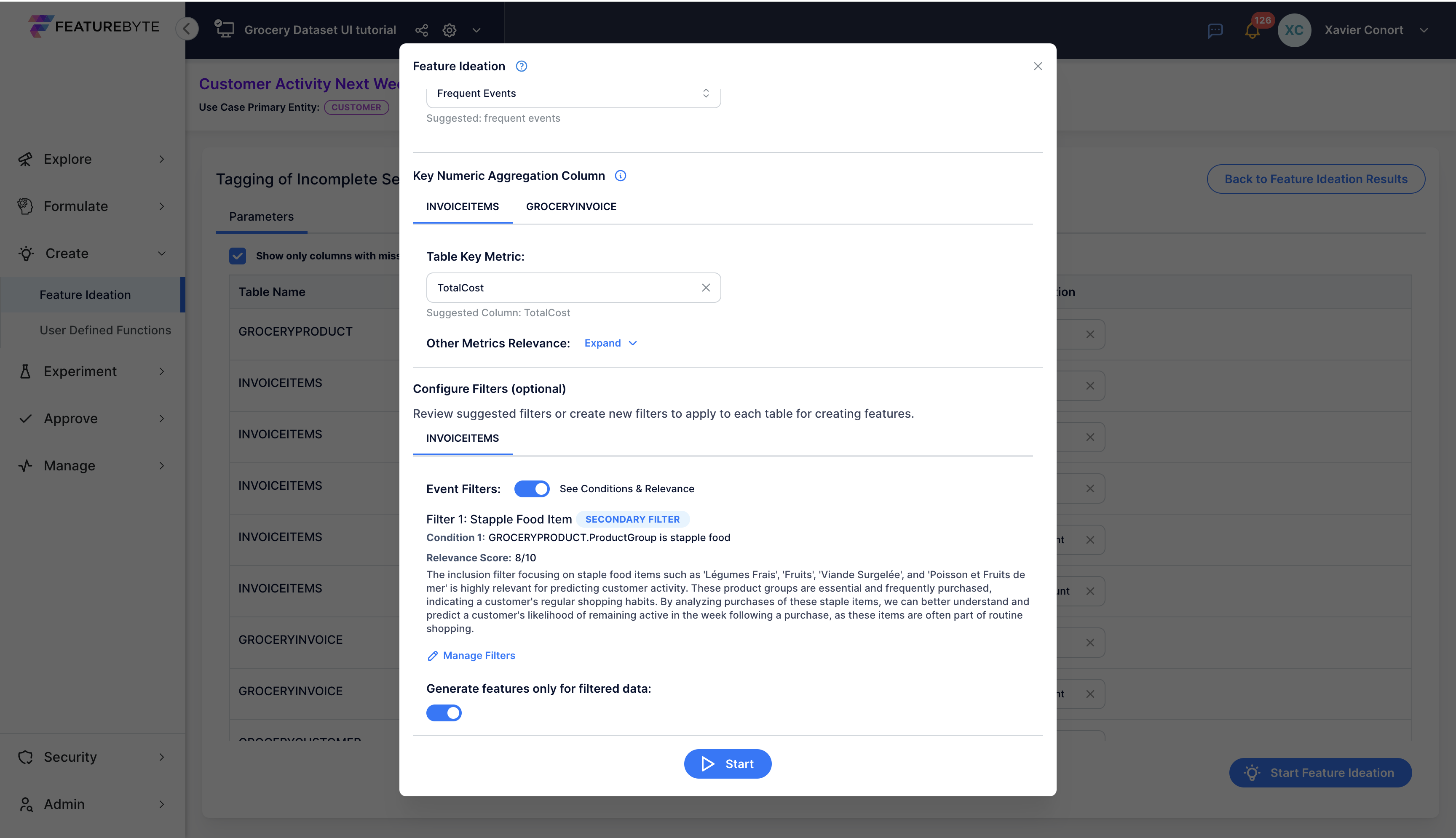
Step 6: Run Feature Ideation with Your New Filer¶
You are now set to run Feature Ideation by clicking ![]()
3. Enhance Text Data with User-Defined Functions¶
Leverage transformer models to generate advanced features from text data using User Defined Functions (UDFs).
We’ll walk you through:
- Registering a SQL UDF in the catalog, using an SBERT Transformer model added to the tutorial's Snowflake data warehouse.
- Starting a feature ideation session using this UDF on the ProductGroup column, which contains descriptive text.
- Generating new features using the transformer model to analyze textual data semantically.
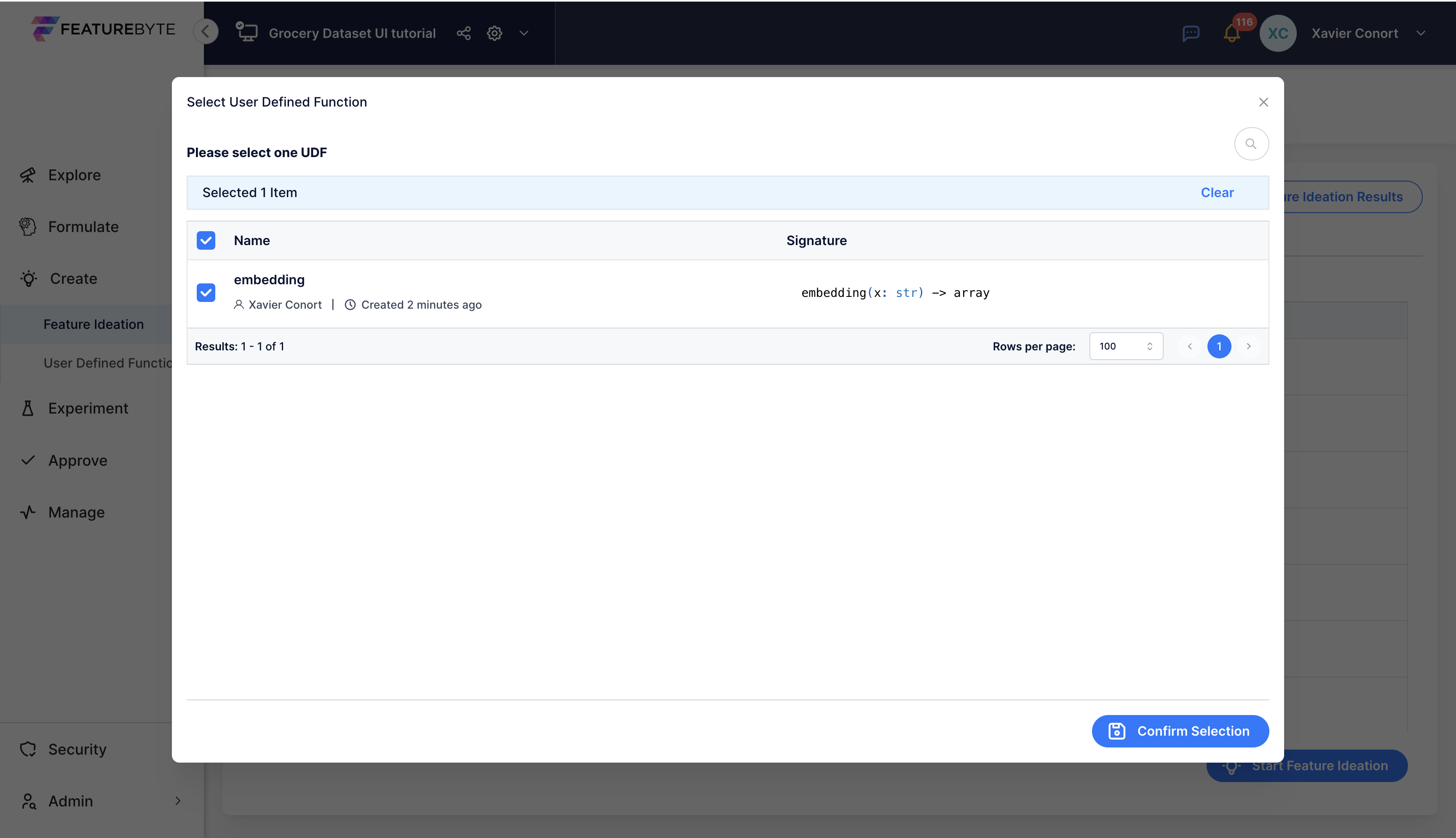
Step 1: Register the UDF in the Catalog.¶
Run this Python code in a notebook.
import featurebyte as fb
fb.use_profile("tutorial")
catalog_name = "Grocery Dataset Tutorial"
catalog = fb.Catalog.activate(catalog_name)
fb.UserDefinedFunction.create(
name='embedding',
sql_function_name='F_SBERT_EMBEDDING',
function_parameters=[fb.FunctionParameter(name="x", dtype=fb.enum.DBVarType.VARCHAR)],
output_dtype=fb.enum.DBVarType.ARRAY,
is_global=False,
)
Step 2: Start a New Ideation¶
Start a new ideation where we will use the SBERT Transformer model by clicking ![]() .
.
Step 3: Apply the Transform to the item's ProductGroup¶
Apply the transformer to the ProductGroup column, which contains descriptive text.
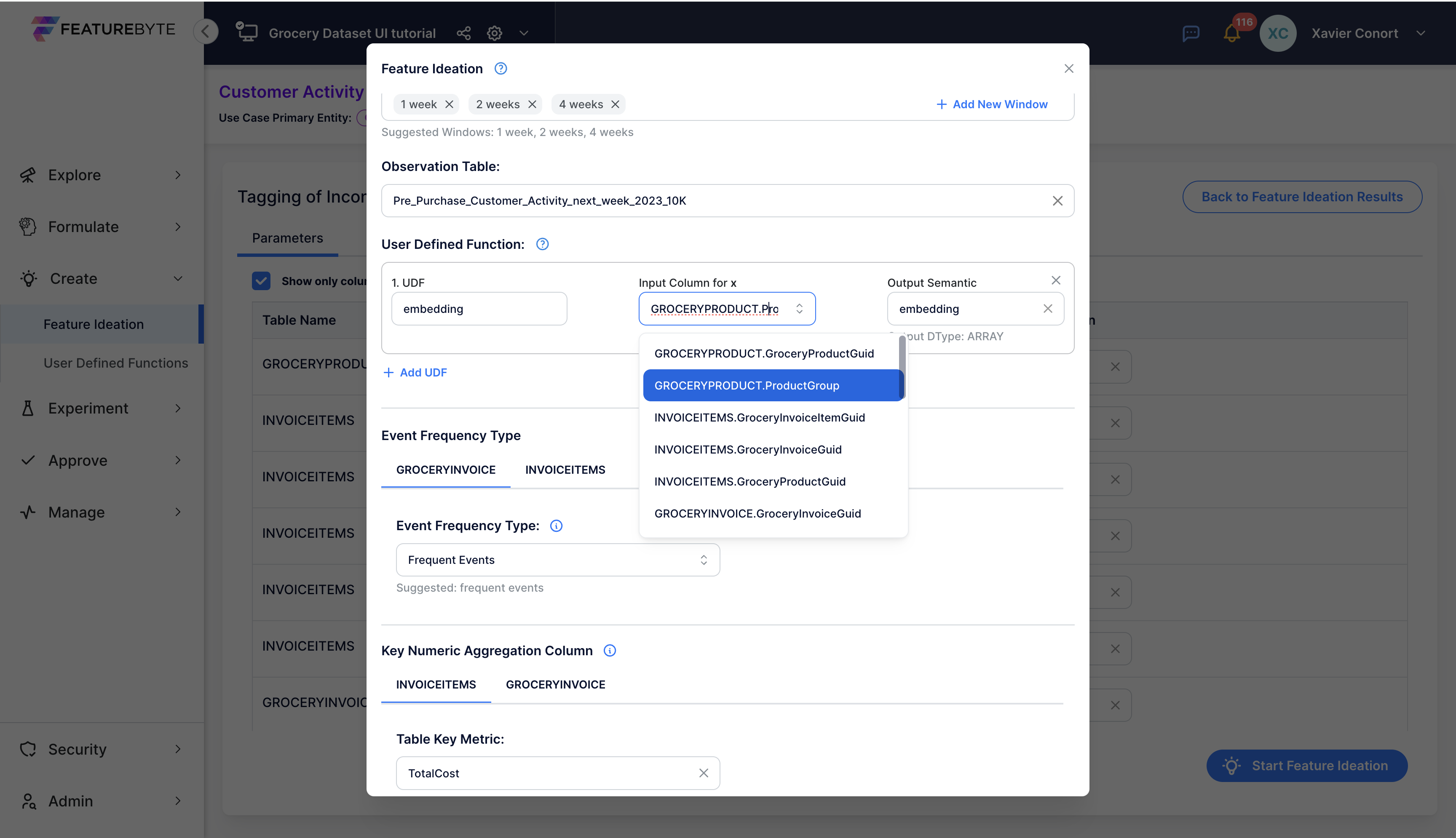
Step 4: Run Feature Ideation¶
You are now set to run Feature Ideation by clicking ![]()
Step 5: Analyze New Features¶
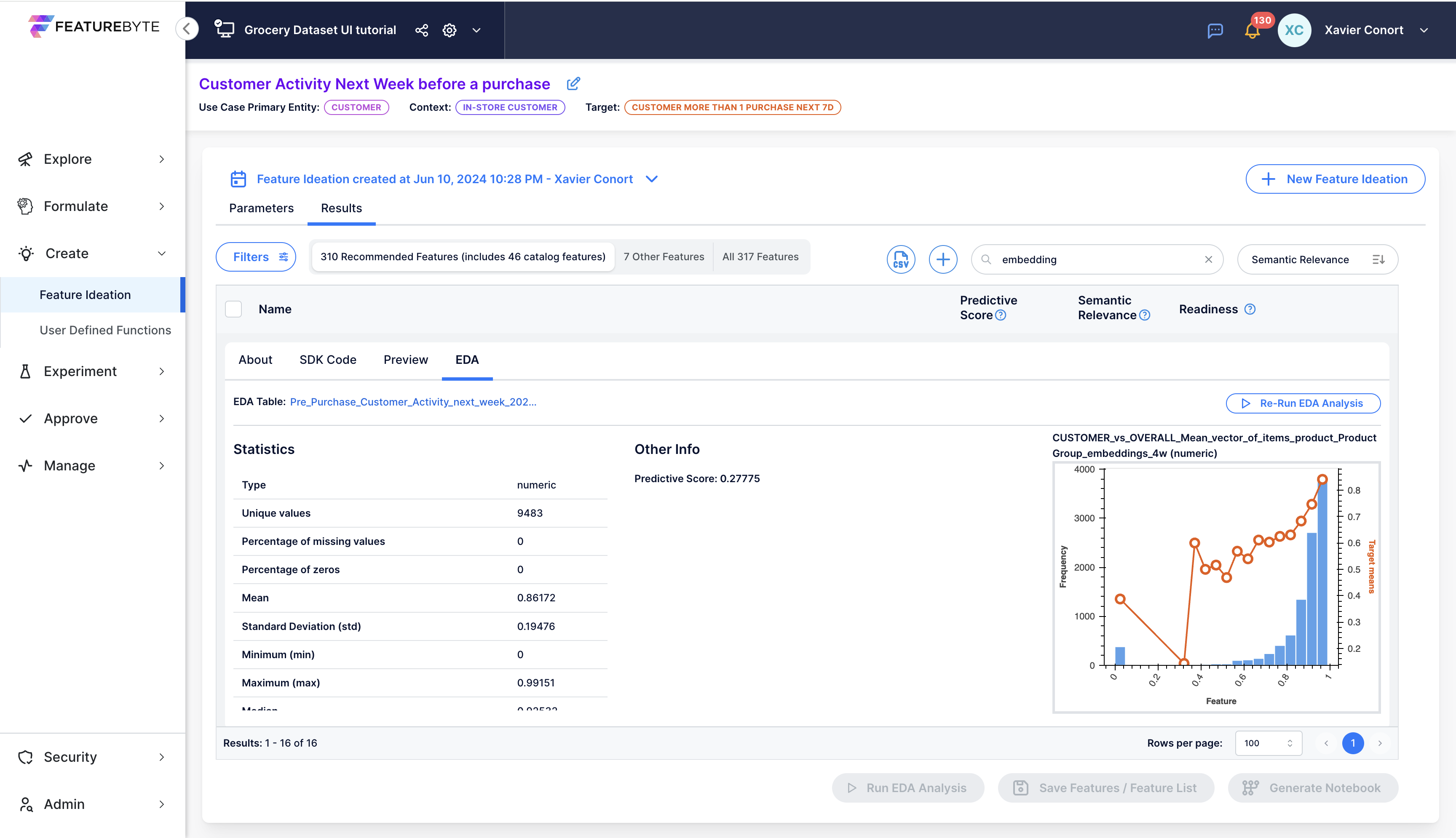
Copilot generated 16 new features using the embedding.
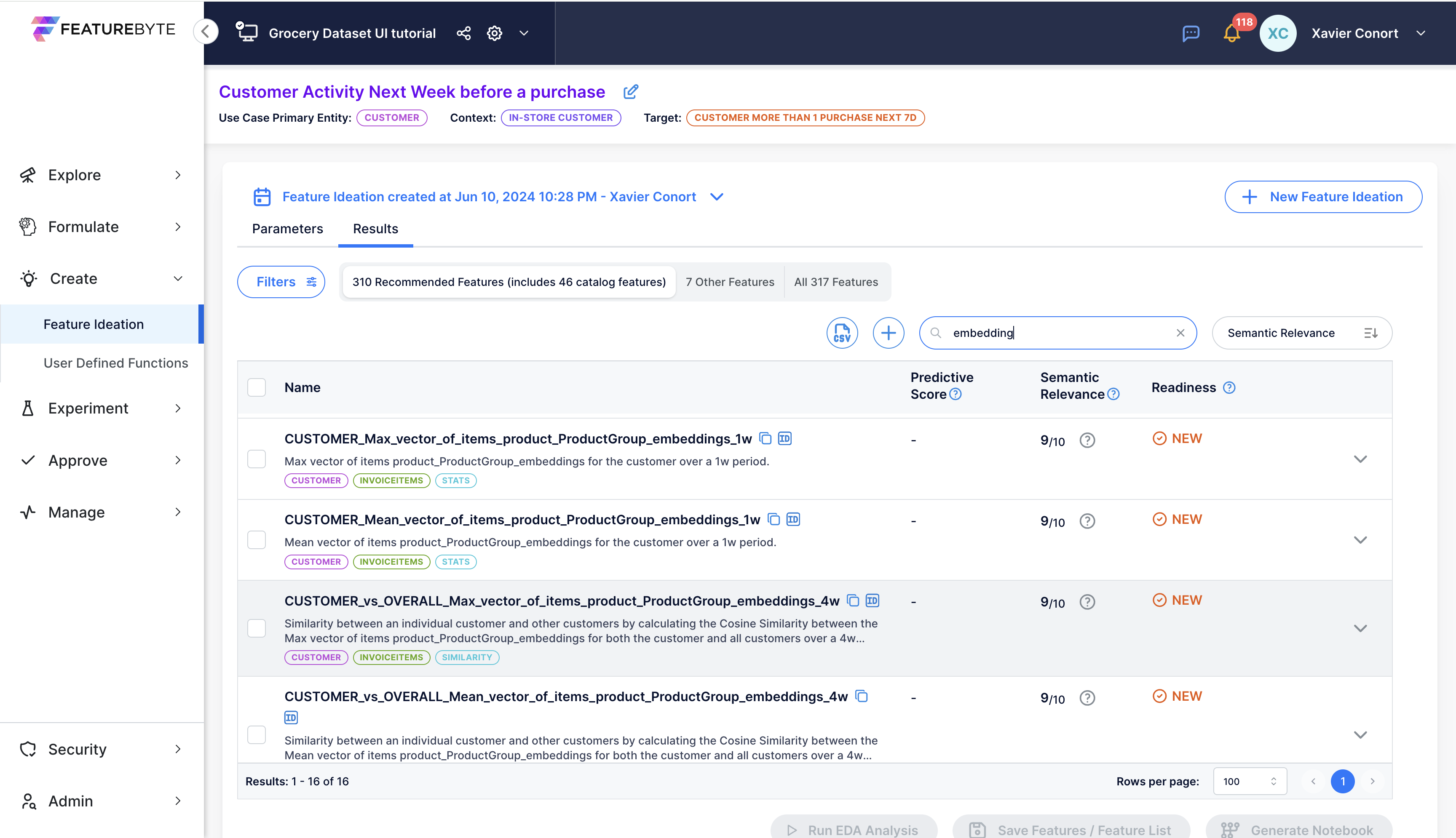
One interesting feature is CUSTOMER_vs_OVERALL_Mean_vector_of_items_product_ProductGroup_embeddings_4w. This feature computes the similarity between an individual customer and other customers by calculating the Cosine Similarity between the Mean vector of items product_ProductGroup_embeddings for both the customer and all customers over a 4w period.
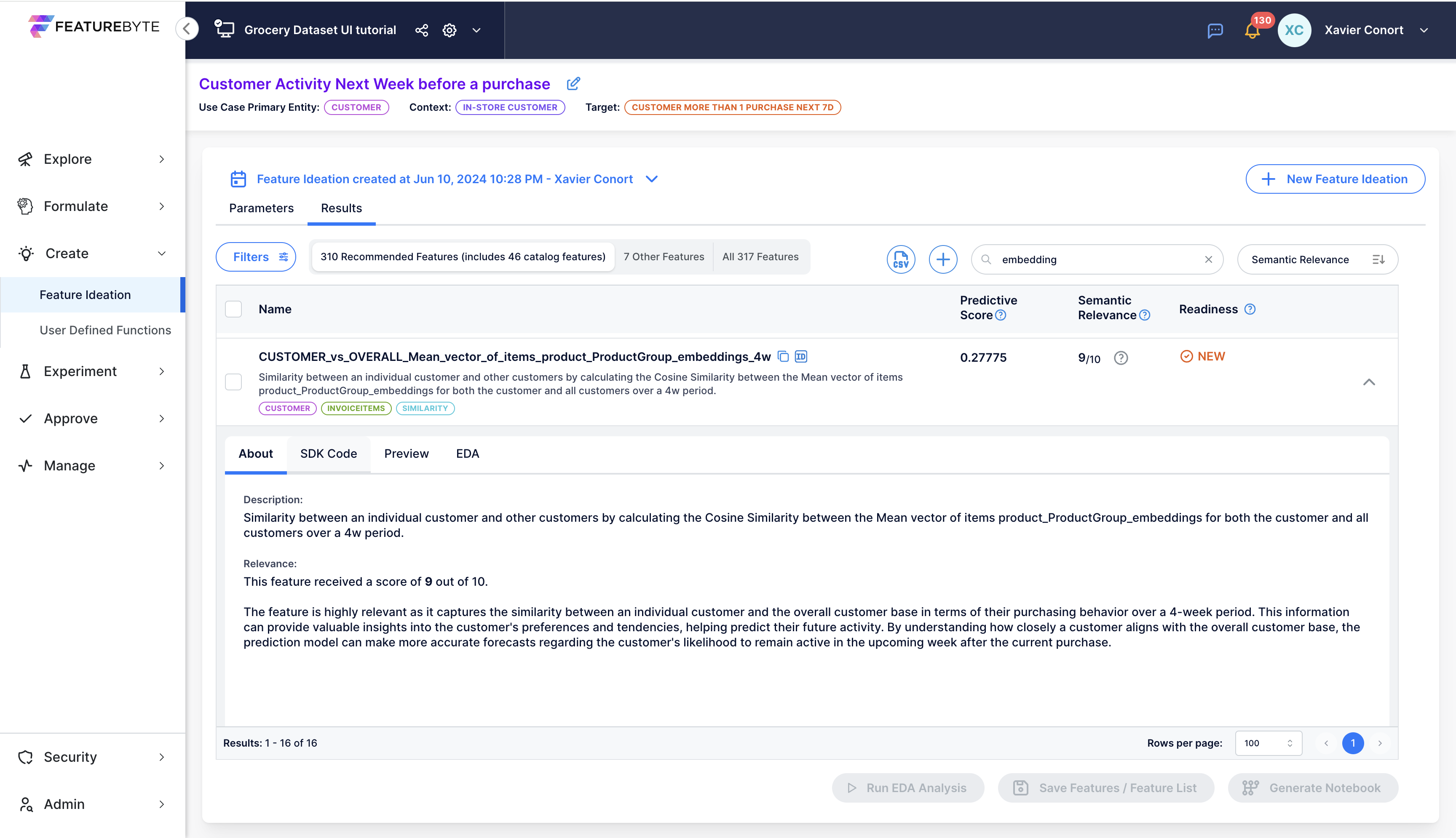
This new feature, while not the most predictive, carries interesting signals that are likely to complement more traditional features and might help build stronger models.