Overview
Introduction¶
This tutorial offers a step-by-step guide on how to leverage transformer models with FeatureByte for text processing and feature engineering.
Throughout this tutorial, we will first provide a concise overview of the architecture, highlighting the integration of transformer models with FeatureByte and your data warehouse. We’ll delve into the specifics of how transformer models, FeatureByte and data warehouse interact.
Next, we will explore multiple deployment strategies for transformer models, helping you select the most appropriate method tailored to your existing infrastructure.
Following that, we will guide you through the process of integrating these deployed transformer models with popular data warehouse solutions such as Snowflake, Spark and Databricks.
Finally, we will demonstrate a practical application by showing you how to leverage the deployed transformer models within FeatureByte SDK. This includes embedding textual features and executing data aggregations, providing you with an understanding of how to harness the power of transformer models within FeatureByte ecosystem.
Architecture¶
To allow FeatureByte to recognize and utilize custom calculations, such as transformers, they need to be first set as SQL functions. These functions can run the transformer model directly, although there might be challenges due to environment setups, dependencies, and potential GPU hardware requirements. Alternatively they can make an HTTP/gRPC request to an external service where the transformer model is deployed.
Thankfully, most modern data warehouses offer support for UDFs or External SQL functions, allowing for the execution of custom code.
The recommended architectural design for FeatureByte + Transformers integration is structured as follows:
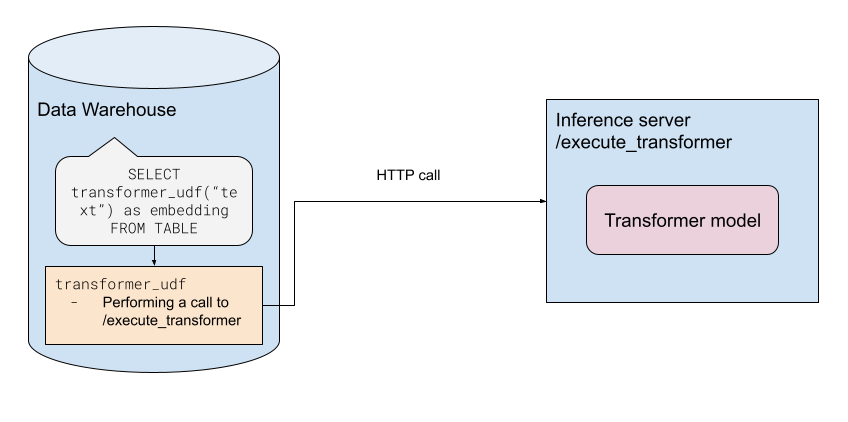
This integration consists of three primary components:
-
Data warehouse: Examples of this include platforms like Snowflake or Databricks (Spark). They are expected to support the creation of custom UDFs.
-
Pretrained transformer model: Examples include Sentence BERT, RoBerta, among others.
-
Inference server: This server makes the transformer model accessible via the HTTP protocol. Support for other protocols, such as gRPC, is also feasible, provided they can be encapsulated within a UDF function.
Setup procedure¶
In conclusion, to empower FeatureByte to invoke a transformer model, the following steps should be undertaken:
-
Deploy the transformer model: Set it up as an HTTP inference endpoint.
-
Create a UDF: This UDF should be capable of receiving a string input (like a textual field from a table) and initiating an HTTP request to the inference endpoint. Each data warehouse has a different way of setting up custom UDF functions, we will cover how to do that in Snowflake and Spark.
-
Use the UDF in FeatreByte SDK: Use registered UDF in FeatureByte SDK via UserDefinedFunction object.
Once you’ve completed these steps, you can run SQL queries such as SELECT transformer_udf(text_column) FROM table or leverage FeatureByte SDK to produce features from text embeddings and perform various aggregations on them.